Hadoop
Hadoop 是 Apache 基金会所开发的分布式系统基础架构,主要解决海量数据的存储、分析计算问题。Hadoop 通常是指一个更广泛的概念:Hadoop 生态圈(包括 HBase、Spark 等)
Hadoop 的三大发型版本
Apache
最原始版本,对于入门学习最好
Cloudera
收费,在大型互联网公司用的比较多
Hortonworks
文档比较好
Hadoop 的优势
高可靠性
Hadoop 底层维护多个数据副本(默认3个),所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失
高扩展性
在集群中分配任务数据,可方便的扩展数以千计的节点
高效性
在 MapReduce 思想下,Hadoop 是并行工作的,以加快任务处理速度
高容错性
自动将失败的任务重新分配执行
1.x 与 2.x 的区别
Hadoop 包含的模块,以及 1.X、2.X 的区别: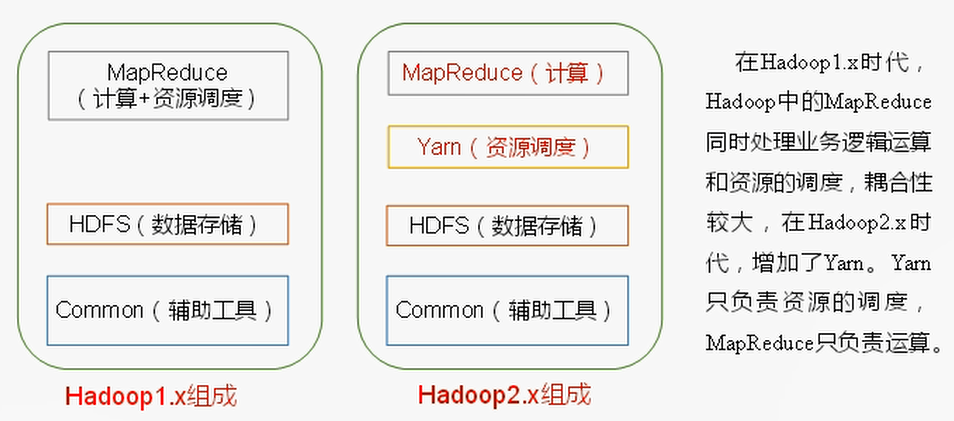
Hadoop 三大组件
HDFS
HDFS 架构:
- NameNode(nn):
相当于一本书的目录;存储文件的元数据,如:文件名、目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的快列表和快所在的 DataNode - DateNode(dn):
相当于目录对应的具体内容;在本地文件系统存储文件块数据,以及块数据的校验和 - Secondary NameNode(2nn):用来监控 HDFS 状态的辅助后台程序,每个一段时间获取 HDFS 元数据快照。
Yarn
ResourceManager(相当于老板) > NodeManager(相当于技术总监)/ApplicationMaster(相当于项目经理)
其中 NodeManager 负责某一个节点,ApplicationMaster 负责节点中的某个任务
ResourceManager
处理客户端请求:管理整个服务器集群资源(磁盘、cpu等)
监控 NodeManager
启动、监控 ApplicationMaster(在集群上运行的任务)
资源的分配、调度NodeManager
管理单个节点上的资源
处理来自 ResourceManager 的命令
处理 ApplicationMaster 的命令ApplicationMaster
负责数据切分
为应用程序申请资源并分配给内部任务
任务的监控和容错Container:为 ApplicationMaster 服务
YARN 中资源的抽象,封装了节点上多维度资源,如:内存、CPU、磁盘、网络等,服务 ApplicationMaster
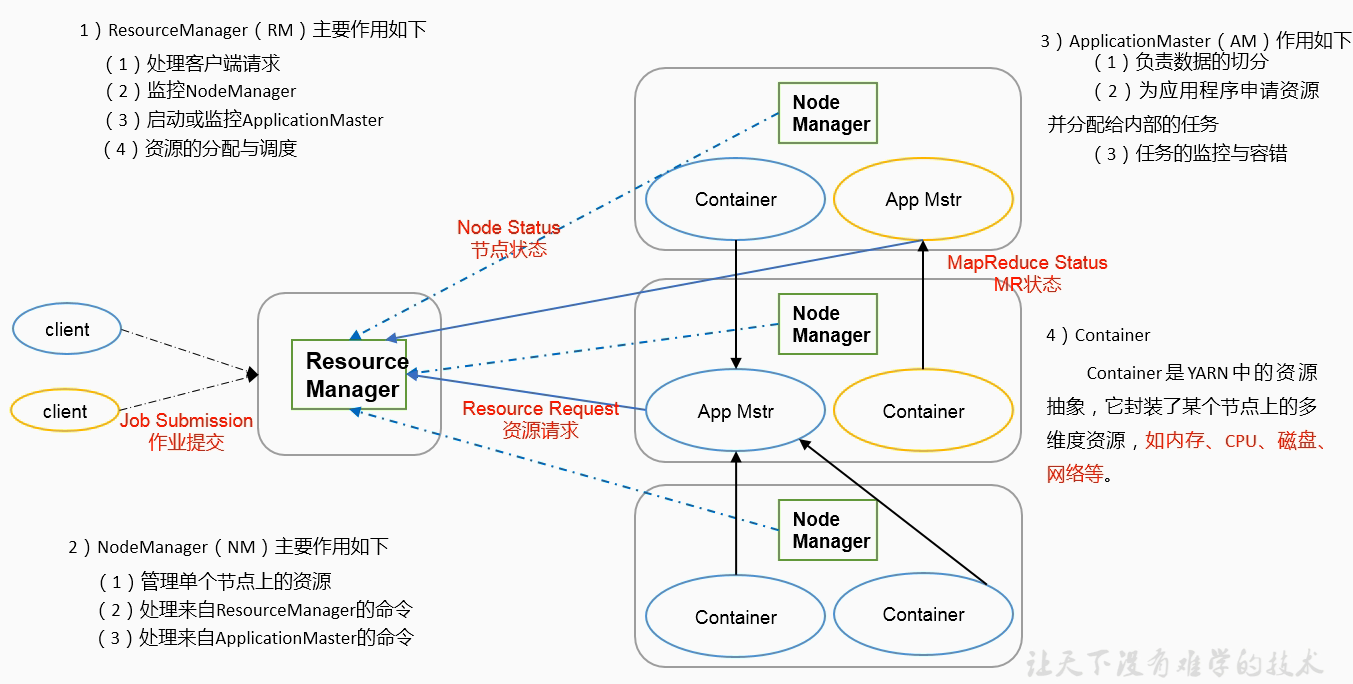
MapReduce
MapReduce 将计算过程分为两个阶段:Map 阶段、Reduce 阶段
- Map 阶段:并行处理输入数据
- Reduce 阶段:对 Map 结果进行汇总
大数据生态体系
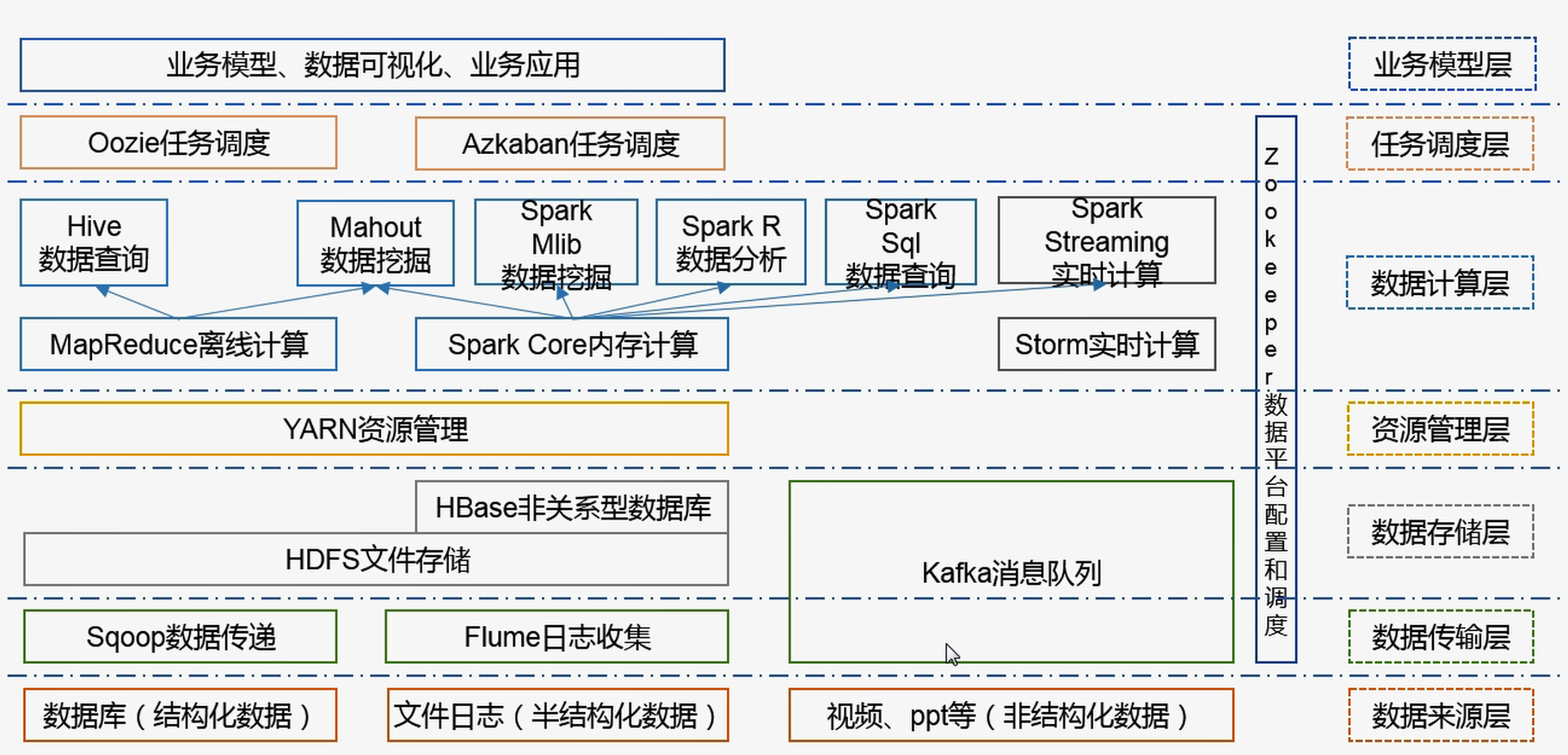
Hadoop 环境搭建
环境准备
CentOS 7
JDK 1.8
Hadoop 2.9.2
CentOS 设置
修改网卡
使用 ROOT 用户,设置 NAT 模式网络连接、设置静态 IP (防止 dhcp 导致 ip 变化)
1 | vim /etc/sysconfig/network-scripts/ifcfg-ens33 |
禁用掉 ipv6,将获取 ip 的方式从 dhcp 改为 static,设置静态 ip 地址 IPADDR、网关 GATEWAY、dns DNS1
1 | TYPE=Ethernet |
注意:网关需要与虚拟机中的 NAT 网卡设置一致!
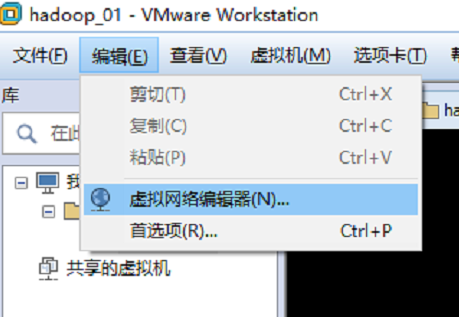
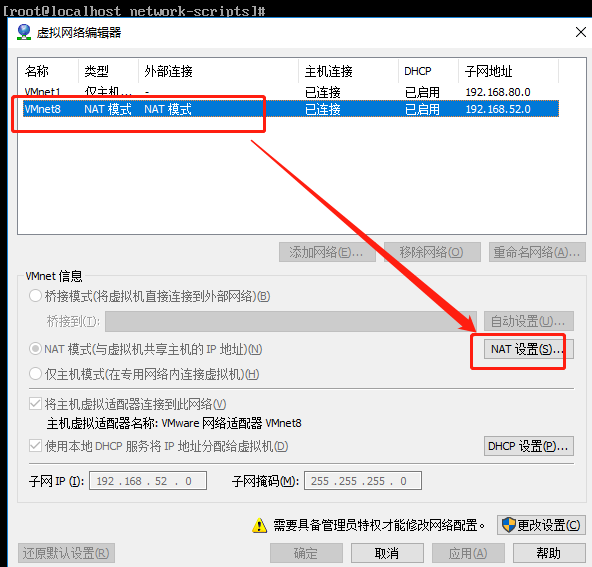
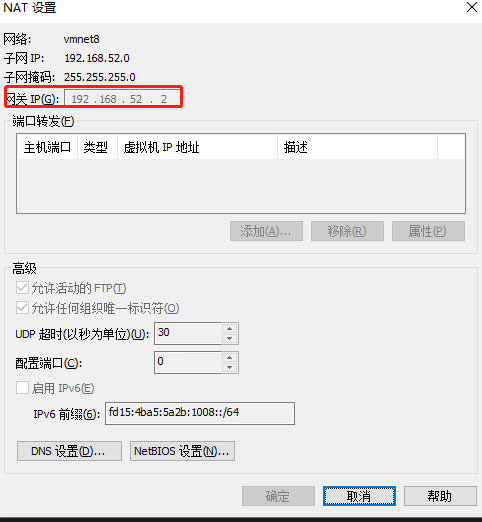
另外,也需要将 VM8 网卡设置一个静态ip,且这个静态 ip 不能与虚拟机的静态 ip一致,必须在一个网段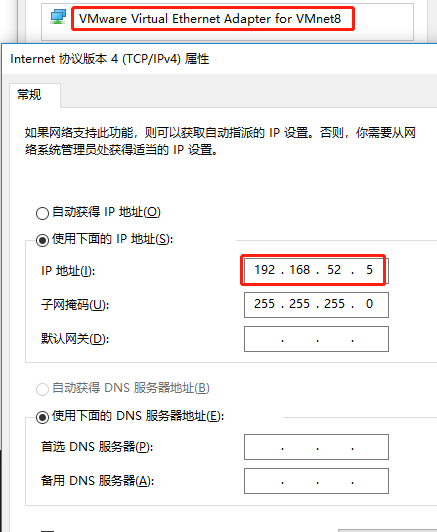
修改 hostname、hosts
1 | vim /etc/sysconfig/network |
1 | vim /etc/hosts |
其中,hosts 文件中的 hadoop02、hadoop03、hadoop04 暂时还没有,先配置上,为后面集群做准备。
安装 JDK、Hadoop
寻找一个文件夹或创建一个空文件夹,作为 jdk、hadoop 的安装目录。本例以 /opt 文件夹为例。
在 /opt 文件夹下创建 module 文件夹,存放 jdk、hadoop 安装文件,创建 software 文件夹,存在 jdk、hadoop 安装包
1 | cd /opt |
利用 xftp 将下载好的 jdk1.8、hadoop 2.9.2 存入 software 文件夹下,解压安装到 module 文件夹下
1 | cd software |
设置 jdk、hadoop 环境变量
1 | vim /etc/profile |
在文件最后添加:
1 | export JAVA_HOME=/opt/module/jdk1.8.0_144 |
应用环境变量:
1 | source /etc/profile |
使用 java、javac、hadoop 命令,测试环境变量设置是否成功
官方案例[grep]
创建一个用于输入的文件夹
任意找一个地方,创建一个 input 文件夹,本例使用与 hadoop 统计目录。
1 | mkdir -p demo/input |
拷贝 hadoop/etc/hadoop/*.xml,到 input 文件夹,用于 grep 案例的输入源
执行官方 demo
在 demo 文件夹下,执行 hadoop 官方 demo
1 | hadoop jar ../hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input/ output 'dfs[a-z.]+' |
解释:
hadoop:以 hadoop 命令执行
jar:执行的是 jar 包
xx.jar:具体 jar 包,本例是 2.7.2 版本的官方 hadoop MapReduce 示例
grep:由于有多个示例,选择执行哪个示例,此处是执行grep案例
input:指明输入示例的文件夹
output:指明输出结果的文件夹,且这个文件夹必须不存在,否则会报文件夹已存在的错误
dfs[a-z.]+:正则过滤
查看控制台输出
1 | 19/09/20 14:29:11 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id |
检查执行结果
1 | [root@hadoop01 demo]# ll output/ |
看到生成了两个文件:part-r-00000、_SUCCESS。
其中,_SUCCESS 文件大小为 0,没有任何内容,只是标记当前执行成功了。
查看 part-r-00000 文件的内容
1 | [root@hadoop01 demo]# cat output/part-r-00000 |
可以看到统计到的符合正则过滤的条件的单词,只有一个,为 dfsadmin。此时如果再次执行刚才的 hadoop 任务,控制台将报错如下:
1 | 19/09/20 14:42:58 INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized |
官方案例[word count]
创建输入源
创建一个 wcinput 用于 word count 案例的输入源,并创建一个 wc.input 文件,输入一些字符串
1 | [root@hadoop01 demo]# mkdir wcinput |
执行 word count 示例
1 | hadoop jar ../hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput |
与上例的区别仅仅是将 grep 换为 wordcount,调整了输入、输出目录,去掉了正则过滤。
查看输出结果:
1 | [root@hadoop01 demo]# cat wcoutput/part-r-00000 |
可以看到每个单词出现的频率