在之前的例子中,完成了一个单机版的 Hadoop + HDFS + YARN 的搭建过程,并成功执行测试成功。
本例中将尝试搭建一个完全分布式的 Hadoop 集群,并验证测试。
Hadoop 集群准备
Hadoop 集群需要准备至少三台 Linux 主机(hadoop02、hadoop03、hadoop04),本例使用 VM 模拟三台 CentOS 7 主机。三台主机环境需要一致,都需要关闭防火墙、设置静态 ip、设置主机名称、JDK、Hadoop 等安装
虚拟机准备
以 hadoop01 为源,克隆三台虚拟机 hadoop02、hadoop03、hadoop04
编写一个集群分发脚本
需要 linux 中事先安装有 rsync 脚本。如果执行命令 rsync 提示没有此命令,在 CentOS 下,执行 yum install -y rsync 安装即可。
需求:循环复制文件到所有节点的相同目录下
在 hadoop01 的 root 用户家目录中,创建一个 bin 目录用于存放脚本,并创建 xsync 脚本文件
1 |
|
需要注意:
- 执行当前脚本的 user 必须有权限操作当前主机待分发的文件或文件夹;也必须在对应的需要分发的主机上拥有此用户,且有操作对应文件夹的权限。
- 待分发的文件、文件夹必须使用绝对路径,以保证同步到对应主机的位置也是正确的
测试分发脚本
执行 xsync /root/bin,在 hadoop02-04 上查看 /root 目录下是否同步了 xsync 脚本
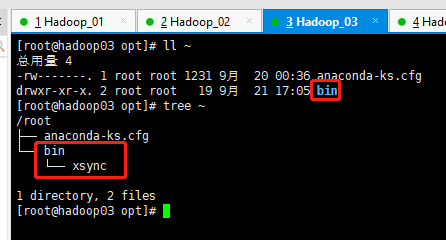
注意:如果 xsync 命令识别不了,可以把 xsync 文件放置在 /usr/local/bin 目录下
集群部署
集群部署规划
| hadoop02 | hadoop03 | hadoop04 | |
|---|---|---|---|
| HDFS | NamdeNode、DataNode | DataNode | SecondaryNameNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
需要保证:
NameNode 和 SecondaryNameNode 不在一台机器上
ResourceManager 上没有 NameNode 和 SecondaryNameNode,防止内存消耗过大
核心配置文件
core-site.xml
在 hadoop02 上,修改 core-site.xml 文件
1 | <configuration> |
HDFS
修改 hadoop-env.sh 中的 JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144
修改 hdfs-site.xml 文件
1 | <configuration> |
YARN
修改 yarn-env.sh、mapred-env.sh 中的 JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144
修改 yarn-site.xml
1 | <configuration> |
修改 mapred-site.xml
1 | <configuration> |
将修改后的配置文件同步到 03、04 上
xsync /opt/module/hadoop-2.7.2/etc/hadoop/ 即可
集群启动
集群单点启动
第一次启动需要格式化 NameNode
bin/hdfs namenode -format
启动
在 hadoop02 上执行 sbin/hadoop-daemon.sh start namenode 及 sbin/hadoop-daemon.sh start datanode
在 hadoop03 上执行 sbin/hadoop-daemon.sh start datanode
在 hadoop04 上执行 sbin/hadoop-daemon.sh start datanode
集群群起
ssh 免密登陆
在 hadoop02 上使用 ssh-keygen 生成秘钥,将生成后的 id_rsa.pub 文件中的内容,拷贝到 hadoop03、hadoop04 中
在 hadoop02 中使用 ssh-copy-id hadoop02、ssh-copy-id hadoop03、ssh-copy-id hadoop04 命令拷贝公钥。
如果不将公钥拷贝到本机,使用 ssh hadoop02 登陆本机时也需要输入密码。
此时即完成 hadoop02 对 03、04 的免密登陆,以同样的方式,在 03、04 上实现免密登陆
群起集群 HDFS
配置 slaves
在 hadoop02 中配置修改 etc/hadoop/slaves 文件,注意:文件内容不允许有空格,不允许有空行
1 | vim etc/hadoop/slaves |
分发到 03、04 上:
xsync etc/hadoop/slaves
停止现有的服务,群起服务
在 hadoop02 中,使用命令 sbin/start-dfs.sh 群起服务
1 | [root@hadoop02 hadoop-2.7.2]# sbin/start-dfs.sh |
使用 jps 在三台服务器上查看启动情况
群起集群 YARN
注意: 由于在 yarn-site.xml 中存在配置 yarn.resourcemanager.hostname 的值为 hadoop03,所以在群起 yarn 时,必须在 hadoop03 上启动,否则会报错
使用命令 sbin/start-yarn.sh 群起 YARN
1 | [root@hadoop03 hadoop-2.7.2]# sbin/start-yarn.sh |
查看启动结果
hadoop02
1 | [root@hadoop02 hadoop-2.7.2]# jps |
hadoop03
1 | [root@hadoop03 hadoop-2.7.2]# jps |
hadoop04
1 | [root@hadoop04 hadoop-2.7.2]# jps |
集群时间同步
使用 crontab 定时同步时间
crontab 定时任务
基本语法:
crontab [command]
| command | 功能 |
|---|---|
| -e | 编辑 crontab 定时任务 |
| -l | 查询 crontab 任务 |
| -r | 删除当前用户所有的 crontab 任务 |
crontab 语法参数
| 含义 | 范围 | |
|---|---|---|
| 第一个 * | 一小时当中的第几分钟 | 0~59 |
| 第二个 * | 一天当中的第几个小时 | 0~23 |
| 第三个 * | 一个月当中的第几天 | 1~31 |
| 第四个 * | 一年当中的第几个月 | 1~12 |
| 第五个 * | 一周当中的星期几 | 0~7(0 和 7 都代表星期日) |
crontab 特殊符号
| 特殊符号 | 含义 |
|---|---|
| * | 代表任何时间 |
| , | 代表不连续的时间。如:“0 8,12,16 *”,代表每天 8点0分,12点0分,16点0分 执行 |
| - | 代表连续时间范围。如:“0 5 1-6”,代表 周一到周六的凌晨5点0分 执行 |
| */n | 代表每隔多久执行一次。如:“10 *”,代表每隔 10 分钟执行一次 |
时间同步
时间服务器(hadoop02)
查看 ntp 是否安装
在 hadoop02 中,执行 rpm -qa | grep ntp,如果没有任何输出,则代表 ntp 没有安装。没有安装的情况下,执行 yum install -y ntp 进行安装。
1 | [root@hadoop02 ~]# rpm -qa | grep ntp |
修改 ntp 配置文件
修改 /etc/ntp.conf 文件
- 授权网段
192.168.x.0-192.168.x.255上的机器都可以从 hadoop02 上查询和同步时间
打开第 17 行的注释,修改网段即可。
将 #restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 修改为 restrict 192.168.233.0 mask 255.255.255.0 nomodify notrap
- 修改集群在局域网中不使用其他互联网时间
将 第21~24行 注释即可。
- 当该节点(hadoop02) 丢失网络连接,依然可用采用本地时间作为时间服务器为集群中的其他节点提供时间同步
在上一步的位置增加如下配置
1 | server 127.127.1.0 |
注意:127.0.0.1 是本地地址127.127.1.0 是回环地址
修改 /etc/sysconfig/ntpd 文件
在文件中增加 SYNC_HWCLOCK=yes,代表 保证硬件时间与系统时间一起同步
启动/重启ntpd
1 | [root@hadoop02 ~]# systemctl status ntpd.service |
设置开机启动:systemctl enable ntpd.service
其他机器(03、04)
在 03、04 上,使用 crontab 同步 02 的时间。
先随便修改一个时间 date -s '2018-11-11 11:11:11',然后编写 crontab 脚本,每分钟从 hadoop02 上同步时间。等待一分钟后再次查看时间。
hadoop 源码编译
在 apache 的 hadoop 官方网站上,hadoop 源码是 32 位的,当需要 64 位的 hadoop 时,就需要重新编译源码
需要准备:
能联网的 CentOS、hadoop 源码包、jdk 64 位,apache-ant、maven、protobuf 序列化框架
本例使用版本:
hadoop:1.7.2
apache-ant:1.9.9
maven:3.0.5
protobuf:2.5.0
jdk:1.8.0_144 64 bit
另外需要安装插件:yum install -y glibc-headers gcc-c++ make cmake openssl ncurses-devel
注意:所有操作必须在 root 用户下完成
安装 protobuf
解压 protobuf-2.5.0 到 /opt/module/,进入 /opt/module/protobuf-2.5.0/ 文件夹,依次执行下列命令:
1 | ./configure |
修改环境变量,设置 protobuf 的环境到 PATH 中。
1 | export LD_LIBRARY_PATH=/opt/module/protobuf-2.5.0 |
验证 protobuf 安装是否成功 protoc --version
编译源码
执行 tar -zxf hadoop-2.7.2-src.tar.gz 解压,然后执行 mvn package -Pdist,native -DskipTests -Dtar,成功后,编译好的 64 位安装包就在 hadoop-2.7.2-src/hadoop-dist/target 下。编译期间报错的话继续在此执行此命令就行。