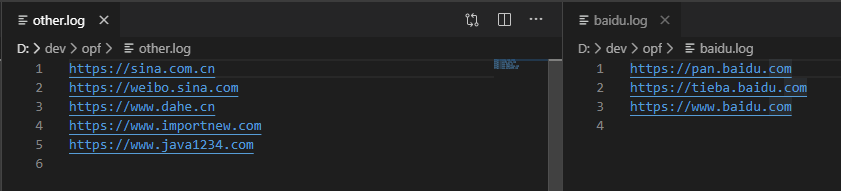
MapTask 流程分为:Read 阶段、Map 阶段、Collect 阶段、溢写阶段、Combine 阶段
ReduceTask 流程分为:Copy 阶段、Merge 阶段、Sort 阶段、Reduce 阶段
工作流程
MapTask 流程
Read 阶段
客户端获取待处理文本,提交之前,获取待处理数据的信息,然后根据参数设置,形成一个任务分配的规划;
提交信息(Job.split、jar、Job.xml);
计算出 MapTask 数量、开启 MapTask,TextInputFormat 开始读取数据
Map 阶段
读取后,返回对应的 KV 数据,并把数据写入到 Mapper 中
Collect 阶段
Mapper 将数据写入环形缓冲区,并进行分区、排序
溢写阶段
将分区、排序后的数据,溢写到文件(分区且区内有序)
Combine 阶段
将溢写后的数据进行归并排序
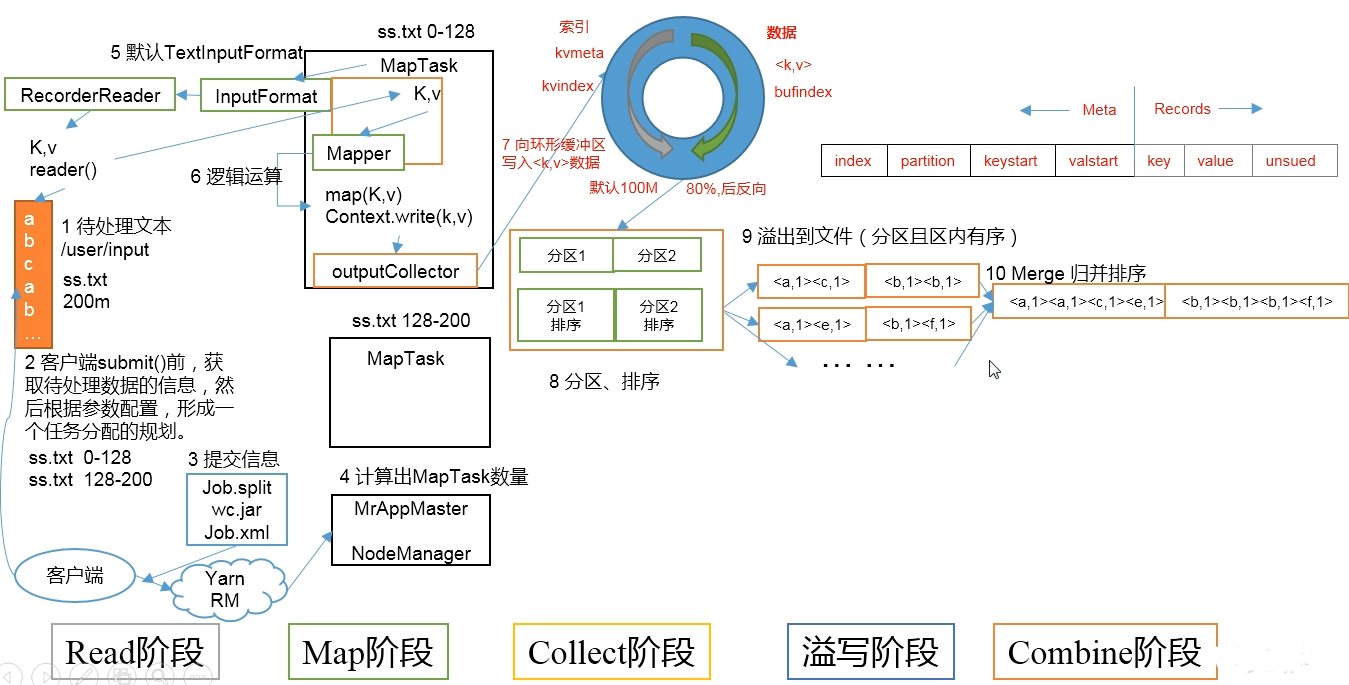
ReduceTask 流程
Copy 阶段
将 MapTask 执行结束后,将对应分区的数据,拷贝到 ReduceTask 中
Merge 阶段
将数据进行归并排序
Sort 阶段
合并 ReduceTask 中的文件,进行归并排序
Reduce 阶段
进行数据处理逻辑,通过 TextOutputFormat 输出到指定位置
ReduceTask 数量
ReduceTask 的并行度,影响着整个 Job 的并发度和执行效率,但是与 MapTask 的并发度,由切片数决定 不同,ReduceTask 的数量是可以手动设置的。job.setNumReduceTasks(2);
ReduceTask 的数量设置,需要根据集群性能去测试调节,并不是一成不变的。
注意事项
- ReduceTask=0,表示没有 Reduce 阶段,输出文件的个数和 Map 个数一致。
- ReduceTask=1,输出文件个数为 1 个(默认)
- 如果数据分布不均匀,就有可能在 Reduce 阶段产生数据倾斜
- ReduceTask 数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有一个 ReduceTask
- 具体需要多少个 ReduceTask,需要根据集群性能而定
- 如果分数区不是 1,但是 ReduceTask 为 1,不会执行分区过程!理由:在 MapTask 源码中,执行分区的前提,是判断 ReduceNum 格式是否大于 1,不大于 1 不执行分区
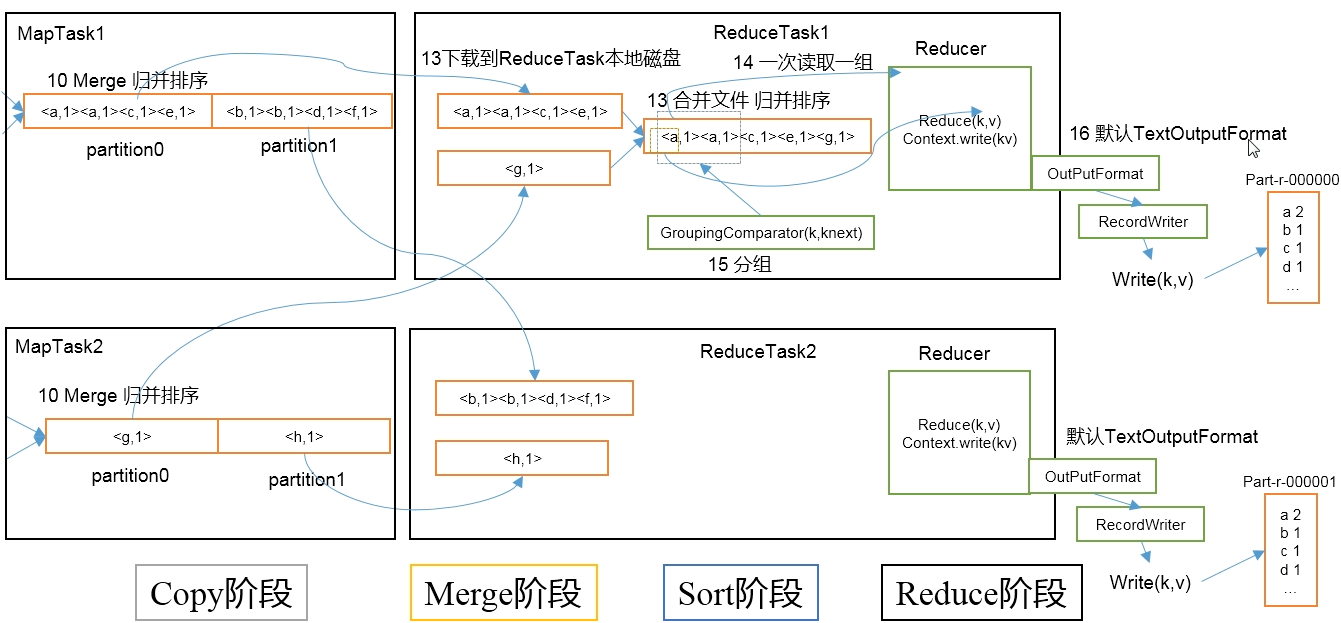
Shuffle 流程
Shuffle 运行在 Map 方法之后,Reduce 方法之前;部分与 Map、Reduce 重合。
Map 阶段
Map 接收之后,数据写入环形缓冲区,对数据进行分区、排序,数据量到达缓冲区 80% 后,开始溢写数据(可选 Combiner 合并);
溢写到磁盘,生成 2 个文件:spill.index、spill.out;
对数据进行归并排序(可选 Combiner 合并)、数据压缩;
将文件写入磁盘,分区输出
Reduce 阶段
从 MapTask 拷贝数据到内存缓冲区(内存不够时溢写到磁盘);
对每个 Map 来的数据进行归并排序;
按照相同的 key 进行分组;
执行 reduce 方法
OutputFormat
OutputFormat 是 MapReduce 输出的基类,所有实现了 MapReduce 输出都实现了 OutputFormat 接口。常见的几个实现类:
TextOutputFormat
默认输出格式,把每条记录斜纹文本行。KV 可以是任意类型,toString 方法可以把它们转为字符串
SequenceFileOutputFormat
可以将将 SequenceFileOutputFormat 的输出,作为后续 MapReduce 任务的输入;格式紧凑,容易压缩
自定义 OutputFormat
自定义实现输出,可定制
自定义实现
需求,根据 日志文件,将包含 baidu.com 的日志输出到 baidu.log,其他的输出到 other.log
Mapper、Reducer
1 | public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> { |
RecordeWriter、OutputFormat
1 | public class CustomerOutputFormat extends FileOutputFormat<Text, NullWritable> { |
Driver
1 | job.setOutputFormatClass(CustomerOutputFormat.class); |
测试结果