Hadoop 为每个作业维护若干个内置计数器,以描述多项指标。
如:记录已处理的字节数和记录数,使用户可以监控已处理的输入数据量和已产生的输出数据量
计数器
计数器 API
枚举方式计数
采用计数器组、计数器名称的方式计数
计数器结果在程序运行后,在控制台上查看
示例
在运行核心业务 MapReduce 之前,往往要先进行数据清洗,清理掉不符合用户要求的数据。清理过程往往只需要运行 Mapper 程序,不需要运行 Reduce 程序
使用一个项目中的日志信息作为输入数据,去除字段长度小于 11 的日志信息
数据信息敏感,不公开
1 | public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> { |
1 | public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { |
查看结果
数据清洗前: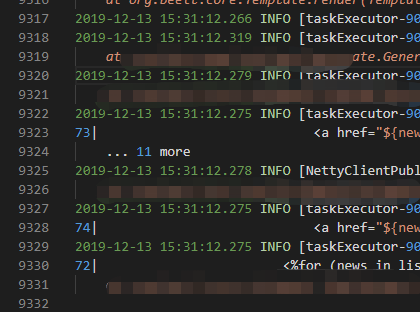
数据清洗后: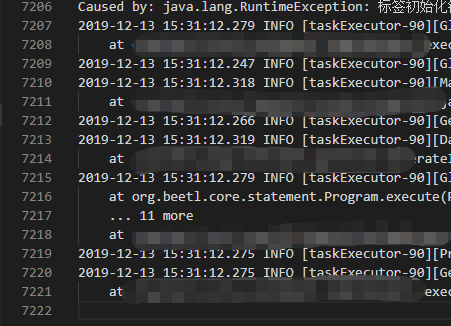
具体更复杂的数据清洗,根据输入数据的不同进行高度定制化,此例只做基础概念思想
压缩
压缩技术能够有效减少底层存储系统(HDFS)读写字节数。压缩提高了网络带宽和磁盘空间的效率。在运行 MapReduce 程序时,IO 操作、网络传输、shuffle 和 merge 要花费大量的时间,尤其是数据规模很大、工作负载密集的情况下,因此使用数据压缩非常重要。
磁盘IO 和网络带宽是 hadoop 的宝贵资源,数据压缩对于节省资源、最小化磁盘 IO、网络传输很有帮助;可以在 任意 MapReduce 阶段启用压缩。压缩也是有代价的。
压缩是提高 hadoop 运行效率的一种优化策略,通过对 Mapper、Reduce 程序运行过程的数据进行压缩,以减少磁盘 IO,提高 MapReduce 程序运行速度。
注意:采用压缩技术,减少了磁盘 IO,但同时增加了 CPU 运算负担,所以,压缩特性运用得当,能提高性能,但是运用不得当也可能降低性能
压缩基本原则
- 运算密集型的任务,少用压缩
- IO 密集型的任务,多用压缩
压缩编码
| 压缩格式 | 是否 hadoop 自带 | 算法 | 文件扩展名 | 是否可切分 | 是否需要修改程序 | 对应编解码器 |
|---|---|---|---|---|---|---|
| DEFLATE | 是 | DEFLATE | .deflate | 否 | 否 | DefaultCodec |
| GZIP | 是 | DEFLATE | .gz | 否 | 否 | GzipCodec |
| bzip2 | 是 | bzip2 | .bz2 | 是 | 否 | BZip2Codec |
| LZO | 否 | LZO | .lzo | 是 | 是,需要建索引、指定输入格式 | LzopCodec |
| Snappy | 否 | Snappy | .snappy | 否 | 否 | SnappyCodec |
性能比较
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3G | 1.8G | 17.5M/S | 58M/S |
| bzip2 | 8.3G | 1.1G | 2.4M/S | 9.5M/S |
| LZO | 8.3G | 2.9G | 49.3M/S | 74.6M/S |
Snappy 在单核 i7 64 位处理器上,压缩速度可以达到 250M/S 以上,解压速度可以达到 500M/S 以上;但是压缩完的文件大小还是很大,且不可以切分。
压缩方式对比
GZip 压缩
优点:
- 压缩率较高,压缩、解压速度较快
- hadoop 本身支持,在应用中处理 gzip 文件和直接处理文本一样
- 大部分 linux 系统都自带 gzip 命令,使用方便
缺点:
不支持切分
应用场景
当每个文件压缩后,文件大小在 130M 以内(即一个块大小的 1.1 倍以内),都可以考虑用 gzip 压缩。
BZip2
优点
- 支持切分
- 压缩率高
- hadoop 自带,使用方便
缺点
压缩、解压速度慢
应用场景
- 对速度要求不高,但是要求较高压缩率;
- 输出后的数据比较大,处理后的速度需要压缩存档减少磁盘空间并且以后数据用的比较少
- 对单个很大的文本文件向压缩以较少存储空间,同时需要支持切分,而且兼容之前的应用程序
LZO
优点
- 压缩、解压速度快
- 压缩率合理
- 支持切分,hadoop 中最流行的压缩格式
- 可以在 linux 中安装 lzop 命令,使用方便
缺点
- 压缩率比 gzip 低
- hadoop 本身不支持,需要安装
- 在应用中需要对 lzo 格式的文件做特殊处理(建索引、指定文件格式)
应用场景
一个很大的文本文件,压缩后还大于 200M 以上的可以考虑。单个文件越大,lzo 优点越明显
Snappy
优点
- 高速压缩、解压
- 压缩率合理
缺点
- 不支持切分
- 压缩率比 gzip 低
- hadoop 本身不支持,需要安装
应用场景
- 当 MapReduce 的 Map 输出数据比较大,作为 Map 到 Reduce 的中间数据压缩格式
- 作为 MapReduce 作业的输出和另外一个 MapReduce 作业的输入
压缩位置的选择
Map 输入之前
在有大量数据并计划重复处理的情况下,应该考虑对输入进行压缩。此时无需指定使用的压缩方式,hadoop 可以检查文件的扩展名,如果扩展名能够匹配,就会使用恰当的编解码方式对文件进行压缩,否则,hadoop 不会使用压缩
Map 处理之后、Reduce 之前
当 Mapper 任务输出的中间数据量很大时,应考虑再此阶段采用压缩技术,能够显著改善内部数据的 shuffle 过程;而 shuffle 过程在 hadoop 处理过程中是消耗资源最多的环节。
如果发现数据量大造成网络传输缓慢,应该考虑使用压缩技术,可以用于 Mapper 输出压缩的格式为:LZO、Snappy。
需要注意:
LZO 是提供 hadoop 压缩数据的通用压缩编解码器。设计目的是达到与硬盘读写速度相当的压缩速度,因此速度是优先考虑的因素,而不是压缩率。
与 gzip 编解码器相比,它的压缩速度是 gzip 的 5 倍,解压速度是 gzip 的 2 倍。
同一个文件用 LZO 压缩后,比用 gzip 压缩后大 50%,但是比压缩前小 25%~50%,这对于改善性能非常有利,Map 阶段完成时间快大概 4 倍。
Reducer 输出
此阶段启用压缩,能够减少要存储的数据量,因此降低所需的磁盘空间。
当 MapReduce 作业形成链条时,第二个作业的输入也以压缩,所以启用压缩同样有效。
压缩参数的配置
| 参数 | 默认值 | 阶段 | 备注 |
|---|---|---|---|
io.compression.codecs(core-site.xml) | DefaultCodec、GzipCodec、BZipCodec | 输入压缩 | hadoop 使用文件扩展名判断是否支持某种编解码器 |
mapreduce.map.output.compress(mapred-site.xml) | false | mapper 输出 | 为 true 时启用压缩 |
mapreduce.map.output.compress.codec(mapred-site.xml) | DefaultCodec | mapper 输出 | 多用 LZO 或 Snappy |
mapreduce.output.fileoutputformat.compress(mapred-site.xml) | false | reduce 输出 | 为 true 时启用压缩 |
mapreduce.output.fileoutputformat.compress.type(mapred-site.xml) | RECORD | reduce 输出 | SequenceFile 输出使用的压缩类型(BLOCK、NONE、RECORD) |
mapreduce.output.fileoutputformat.compress.codec(mapred-site.xml) | DefaultCodec | reduce 输出 | 具体的压缩编码 |
示例
CompressionCodec 有两个方法可以用于轻松的压缩、解压数据。
想要对正在被写入一个输出流的数据进行压缩,可以使用 createOutputStream 方法创建一个 CompressionOutputStream,将其以压缩格式写入底层的流。
想要对输入数据进行嘉业,可以使用 createInputStream 方法床架一个 CompressionInputStream,从而从底层的流读取未压缩的数据
压缩测试
输入数据:使用之前 CombinerTextInputFormat 示例 中的 输入数据 d.txt 作为压缩测试的输入数据,测试不同压缩方式下的压缩率、耗时等。
1 | public static void main(String[] args) throws Exception{ |
测试结果
可见压缩前后数据大小的区别非常明显
解压测试
1 | public static void main(String[] args) throws Exception{ |
测试结果
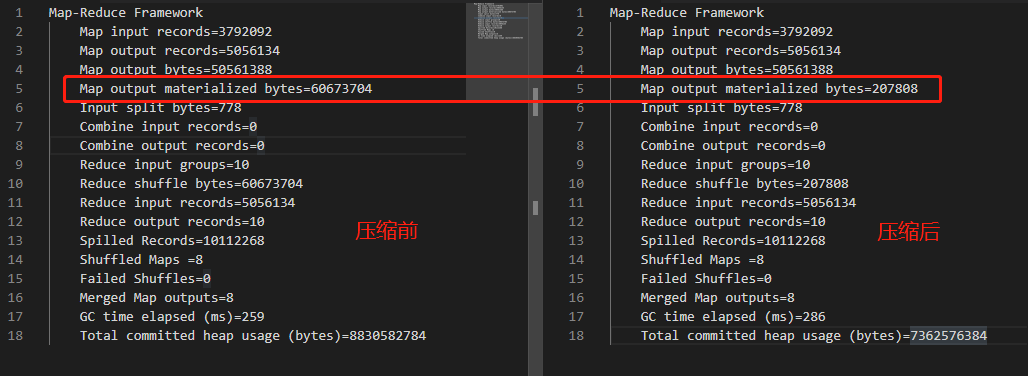
Map 输出端采用压缩
即是 MapReduce 的输入、输出文件都是未压缩的文件,仍然可以对 Map 任务的中间结果输出做压缩(原因是 Map 结束后要将文件写入磁盘,并通过网络传输到 Reduce 节点,对其压缩可以提高很多性能)
Hadoop 源码支持的压缩格式有:BZip2Codec、DefaultCodec
基于 CombinerTextInputFormat 示例 进行操作。
首先执行 wordcount 实例,查看控制台 MapReduce 过程的字节数
1 | Map-Reduce Framework |
修改 WordCountDriver,增加压缩配置
1 | // 开启压缩 |
再次运行测试,查看控制台 MapReduce 过程字节数(开启压缩后的程序会比开启压缩前要慢很多)
1 | Map-Reduce Framework |
Reduce 输出压缩
还是以上例为例,将 map 压缩注释掉(为了快速测试 reduce 压缩,省去 map 压缩的等待时间),增加如下配置,开启 reduce 压缩
1 | // 开启 reduce 压缩 |
测试三种压缩方式的执行耗时,由于文件过小,实际总耗时相差无几。
1 | reduce bz2 总耗时:9132 |