HDFS、MapReduce、Yarn 是 Hadoop 的三大模块,其中,HDFS 负责存储,MapReduce 负责计算,Yarn 负责资源调度
MapReduce
MapReduce 是一个 分布式运算程序的编程框架,是用户开发 基于Hadoop的数据分析应用的核心框架。
MapReduce 的核心功能,是将 用户编写的业务逻辑代码,和自带的默认组件,整合成一个完整的分布式运算程序,并发的运行在一个 Hadoop 集群上。
优缺点
优点
易于编程
简单地实现一些接口,就可以完成一个分布式程序。这个分布式程序可以分布到大量的廉价 pc 机器上运行。也就是说,写一个分布式程序和写一个串行程序一模一样。 就是因为这个特点,使得MapReduce编程变得非常流行。
良好的扩展性
当计算资源不能得到满足时,可以通过简单的扩展机器来扩展计算能力。
高容错性
MapReduce 设计初衷,就是使程序能够部署在廉价的 pc 机器上,这就要求它具有很高的容错性。
如:一台机器挂掉了,它可以把上面的计算任务转移到另外一个节点上,不至于这个任务运行失败,而且这个过程不需要人工参与,完全由 Hadoop 内部完成。
适合 PB 级以上海量数据离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点
不擅长实时计算
无法像 MySQL 一样,在毫秒级或秒级内返回结果
不擅长流式计算
流式计算的输入数据是动态的,而 MapReduce 的输入数据集的静态的,不能动态变化。这是由 MapReduce 自身的设计特点决定的。
不擅长 DAG(有向图) 计算
有向图:多个应用程序存在依赖关系,后一个程序的输入是前一个程序的输出。
MapReduce 可以做 DAG 计算,但是不推荐。原因的每个 MapReduce 的输出结果都会写入磁盘,会造成大量的磁盘 IO,导致性能低下。
核心思想
MapReduce 运算程序一般分为两个阶段:Map 阶段(分),Reduce 阶段(合)。
Map 阶段的兵法 MapTask,完全并发运行,互不相干。
Reduce 阶段的并发 ReduceTask,完全并发运行,互补相干。但是它们的数据依赖于上一阶段的所有 MapTask 并发实例的输出。
MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果业务逻辑复杂,只能多个 MapReduce 程序串行运行。
例如: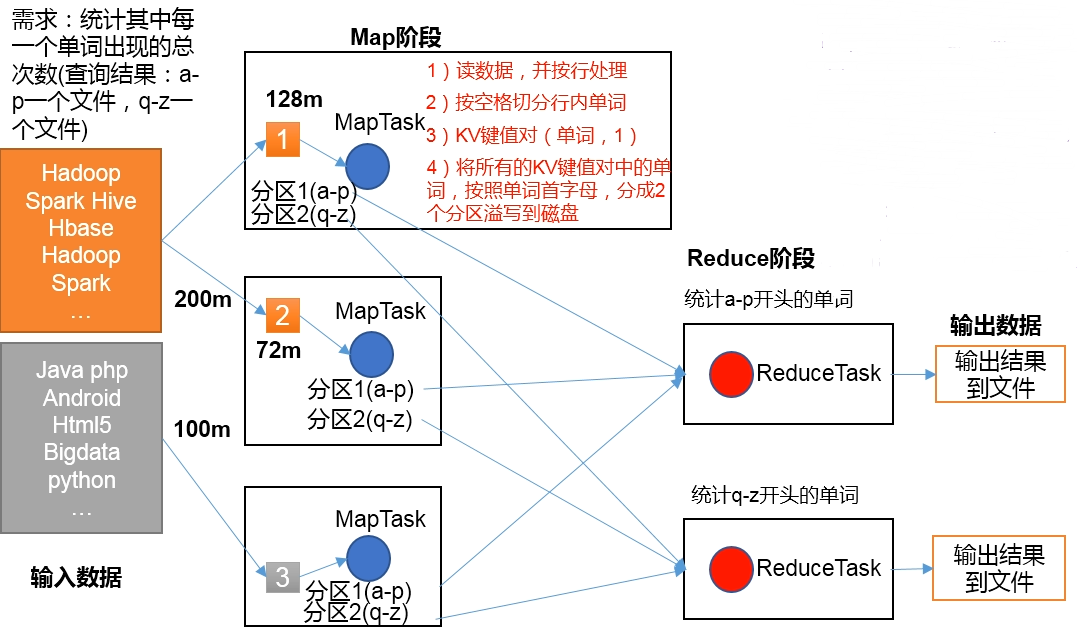
MapReduce 进程
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
MrAppMaster:负责整个程序的过程调度以及正太协调
MapTask:负责 Map 阶段的整个数据处理流程
ReduceTask:负责 Reduce 阶段的整个数据处理流程
Hadoop 数据序列化类型
| Java 类型 | Hadoop Writable 类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| array | ArrayWritable |
MapReduce 编程规范
MapReduce 编程分为三个部分: Mapper、Reducer、Driver
Mapper 阶段
- 用户自定义的 Mapper 要继承自己的父类
- Mapper 的数据数据是 KV 对形式,KV 类型自定义
- Mapper 的业务逻辑写在 map() 方法中
- Mapper 的输出数据是 KV 对形式,KV 类型自定义
- map() 方法对每个 KV 只调用一次
Reducer 阶段
- 用户自定义的 Reducer 要继承自己的父类
- Reducer 的输入类型对应 Mapper 的输出数据类型,也是 KV
- Reducer 的业务逻辑写在对应的 reduce() 方法中
- reduce() 方法对每个 KV 只调用一次
Driver 阶段
相当于 YARN 集群的客户端,用于提交整个程序到 YARN 集群,提交的是封装了 MapReduce 程序相关运行参数的 Job 对象
WordCount(Demo)
需求:给定一个文本文件 README.txt,统计文本中每个单词出现的总次数
流程分析:
Mapper 阶段
- 将 MapTask 传给我们的文本内容转换为 String
- 根据空格将单词分为单词
- 将单词输出为 <单词, 1> (如果有相同的单词,输出的也是 <单词, 1>, 因为 map 阶段只做拆分,不做合并)
Reducer 阶段
- 汇总各个 key 的个数
- 输出该 key 的总次数
Driver
- 获取配置信息,获取 job 对象实例
- 指定本程序的 jar 包所在的本地路径
- 关联 Mapper、Reducer 业务类
- 指定 Mapper 输出的 KV 类型
- 指定最终输出的数据 KV 类型
- 指定 job 的原始文件所在目录
- 指定 job 的输出结果所在目录
- 提交 job
Mapper 实现
1 | /** |
Reducer 实现
1 | /** |
Driver 实现
1 | public class WordCountDriver { |
执行测试
运行时可以看到打印信息如下: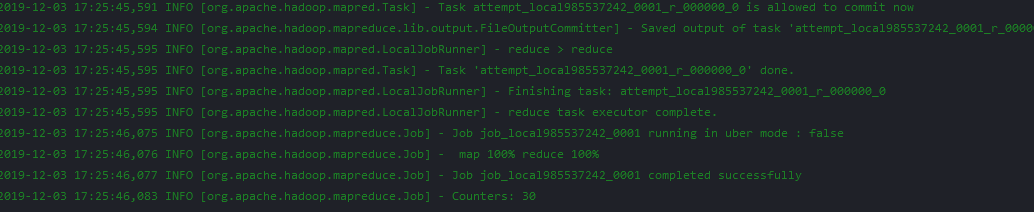
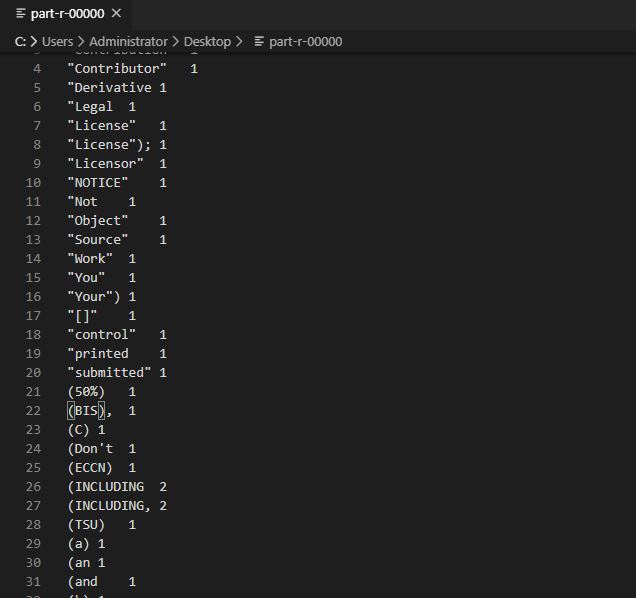
打开执行后的 part-r-00000 文件如下: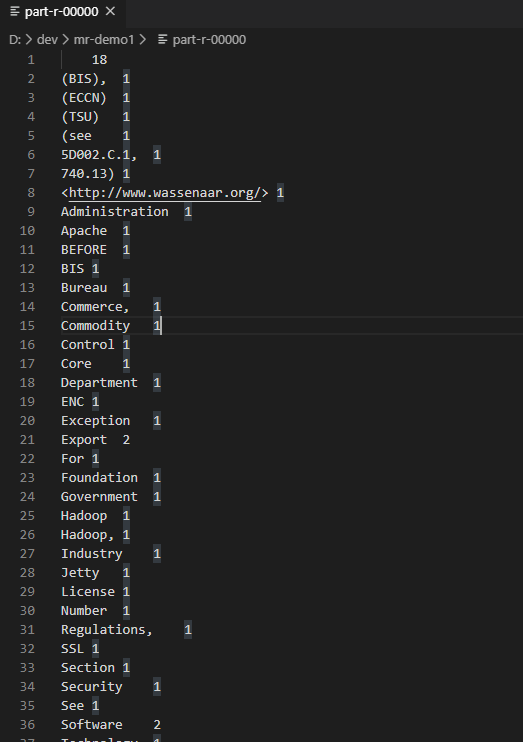
在集群中运行
将 Driver 的输入、输出路径改为参数获取方式:
1 | // 指定 job 的输入文件所在目录 |
在 pom.xml 文件中增加如下配置:
1 | <build> |
然后使用 mvn package 打包后,会生成两个文件:
1 | hadoop-1.0-SNAPSHOT.jar |
第一个 jar 是没有 hadoop 依赖的,第二个 jar 是有 hadoop 依赖的。
由于在 hadoop 集群上运行,所以可以使用第一个 jar。如果服务器上没有 hadoop 依赖,则使用第二个 jar 即可。
将第一个 jar 上传至 hadoop,由于使用的是 hadoop 集群,所以输入、输出路径均为 HDFS 路径。
运行测试:
1 | [root@hadoop02 hadoop-2.7.2]# hadoop jar hadoop-1.0-SNAPSHOT.jar com.laiyy.study.mapreduce.wordcount.WordCountDriver /laiyy /laiyy/output |
执行结束后,查看 HDFS 中 /laiyy/output 文件夹内容,并下载 part-r-0000 文件,查看文件输出.