在了解了常见的 InputFormat,及其处理分片的方式后,通过集成 FileInputFormat 自实现了一个自定义的 InputFormat,并通过自实现的 InputFormat,完成了一个对小文件的汇总合并工作。
那么此时,就需要深入了解一下 MapReduce 的具体工作流程
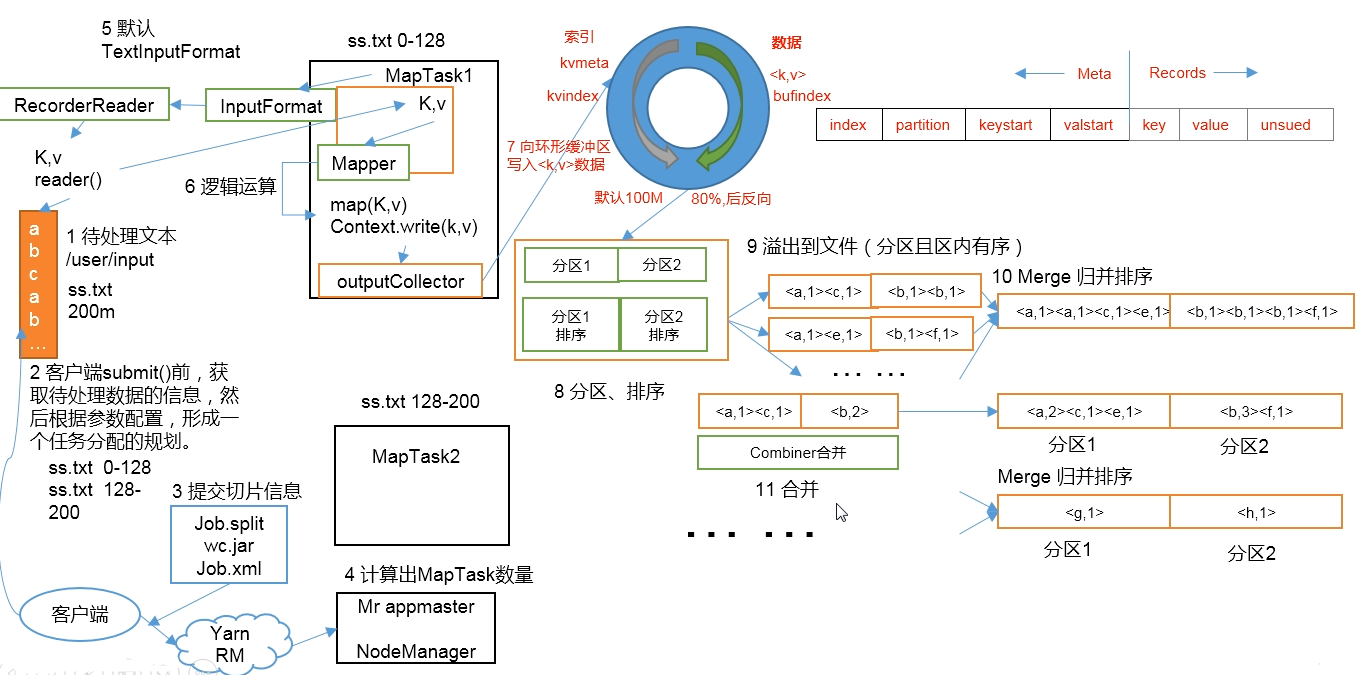
MapReduce 工作流程
- 准备待处理文件
- 客户端进行 submit 之前,获取待处理数据的信息,根据参数配置,形成一份任务分配的规划(即 切片信息)
- 提交切片信息(job.split) 和 jar(集群模式下提交)、Job.xml
- 计算 MapTask 的数量(Yarn 中会先创建一个 MrAppMaster,根据 job.split 决定分配 MapTask 的数量)
- 执行 InputFormat 的 initialize 方法,获取文件、分片信息
- 执行 Mapper 操作
- 向环形缓冲区(默认 100M)中写入 KV 数据(日志中会打印 0%、50% 等信息);缓冲区右侧是数据,左侧是数据的元数据(索引、位置、k-v 的起始位置等)。当缓冲区达到 80% 时,数据溢写到磁盘,且左右两侧数据清空,并反向写入数据。
- 进行分区、排序
- 溢出到文件(分区、且区内有序)
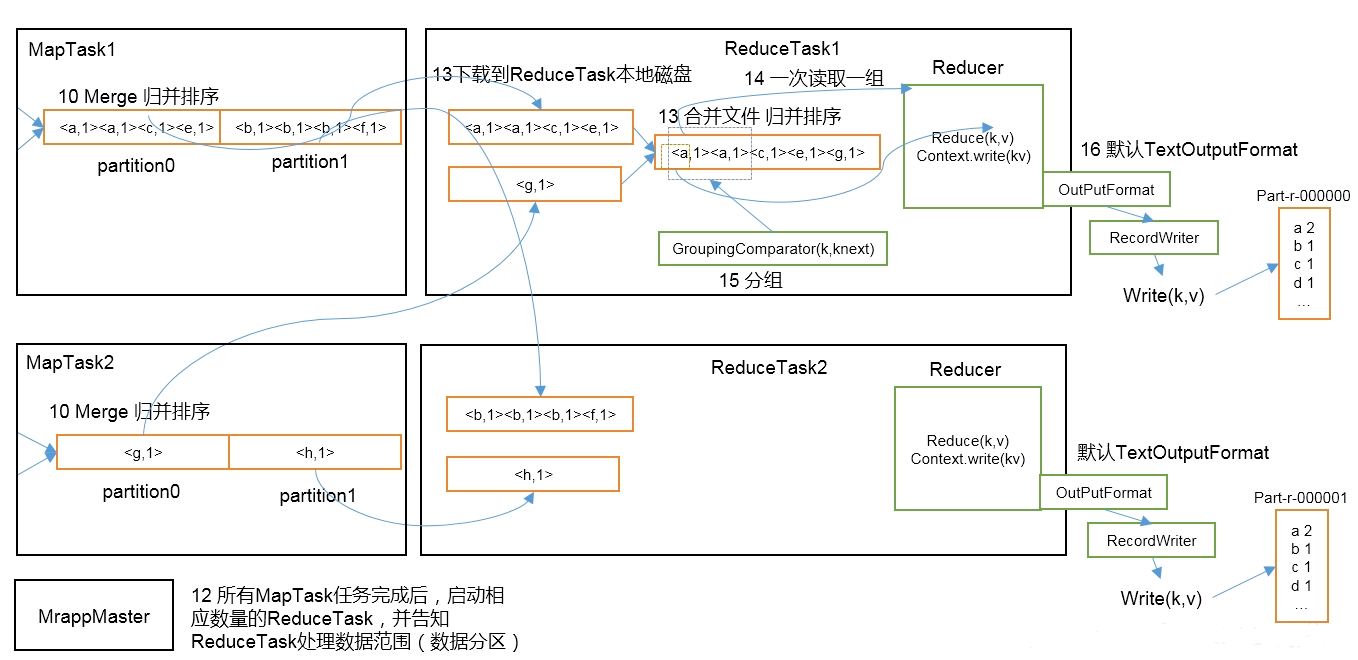
- 归并排序并合并文件(Reducer)
- 所有的 MapTask 任务完成后,启动 ReduceTask(数量由 MapTask 分区数量决定),并告知 ReduceTask 处理数据的范围(数据分区)
- 将 MapTask 处理后的数据下载到 ReduceTask 本地磁盘
- 将 ReduceTask 的文件进行归并排序,合并为一个文件后,进行 Reduce 操作
- 通过 OutputFormat 写出文件
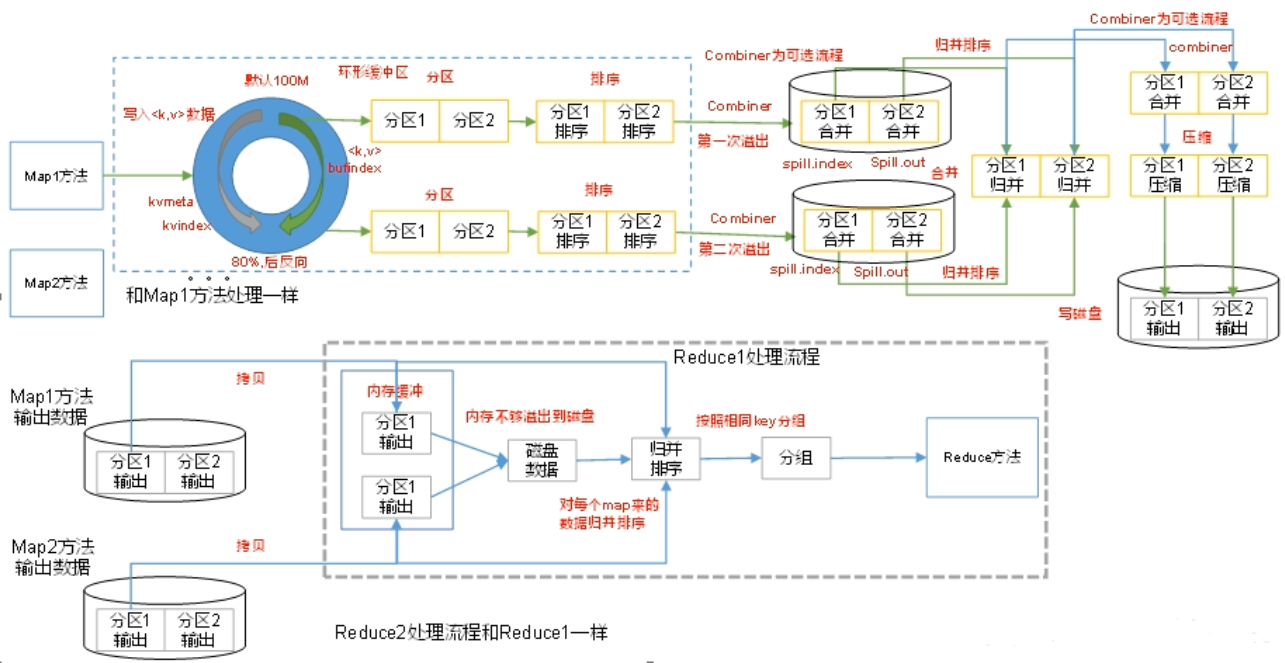
Shuffle
Map 方法之后,Reduce 方法之前的数据处理,称之为 Shuffle。此操作涉及:分区、排序、归并排序、数据压缩等。
Partition 分区
分区:将统计的结果,按照不同的条件,输出到不同的文件中。默认分区实现:HashPartitioner。
1 | public class HashPartitioner<K, V> extends Partitioner<K, V> { |
由源码可知,默认的分区是根据 key 的HashCode 对 ReduceTasks 个数取模得到的。用户没有办法控制哪个 key 存储到哪个分区。
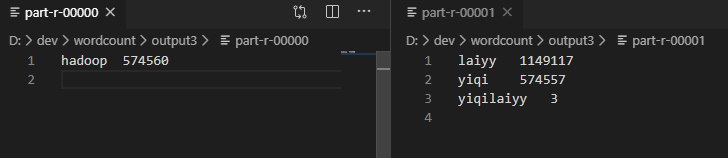
修改 WordCount 实例,增加配置: job.setNumReduceTasks(2);,再次运行。当 Mapper 进入 context.write(key, value); 时,将进行分区操作。
1 | // MapTask.java |
运行后查看输出目录,发现有 2 个文件,证明分区成功。
自定义分区
实现步骤:
- 自定义类,继承
Partitioner,重写getPartition方法 - 在 Job 驱动中,设置自定义的 Partitioner
- 根据自定义的 Partitioner 逻辑,设置相应数量的 ReduceTask
需求:使用之前 序列化实例 的输入数据,实现 按照手机号归属地不同,输出的不同的文件中。
期望输出:如果手机号以 偶数 结尾,输入的一个文件,否则输出到不同文件。 根据文件内容,手机号以 0、3、5、7、8 结尾,则 0、8 输出到一个文件,其余的每个手机号一个文件。
注意:在使用自定义的 Partitioner 时,必须要指定 ReduceTask 的数量(setNumReduceTasks),否则只会输出一个文件,且所有数据都在这一个文件中!
如果指定的 ReduceTask 数量,小于 Partitioner 中的数量,则会出现 IO 异常,原因:无法确定输出结果用哪个 ReduceTask 输出。
如果指定的 ReduceTask 数量,大于 Partitioner 中的数量,不会报错,但是会出现几个空文件
分区号必须从0开始,逐一累加
在之前
序列化实例的基础上,进行修改
- 自定义 Partitioner
1 | public class FlowBanPartitioner extends Partitioner<Text, FlowBean> { |
- 修改 Driver
1 | // 修改 Partitioner |
- 测试运行