除了管理表、内部表外,常用的表还有分区表。分区表实际上是一个 HDFS 文件夹,文件夹下存放的是对应分区的数据
分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区的所有数据。
Hive 中的分区就是分目录,把一个大的数据集根据业务需要,分隔成小的数据集。
在查询的时候,通过 WHERE 字句中的表达式选择查询所需要的指定分区,这样的查询效率会提高很多。
基本操作
创建一个表,指定分区
1 | create table dept_partition( |
加载数据查看问题
1 | hive (default)> load data local inpath '/opt/module/hive/tmp_data/dept.txt' into table dept_partition; |
可以看到,数据加载失败了。原因是我们创建表的时候,设置了根据 month 分区,而在加载数据的时候没有指定分区列造成的。
按照分区加载数据
1 | hive (default)> load data local inpath '/opt/module/hive/tmp_data/dept.txt' into table dept_partition partition(month='2019-07'); |
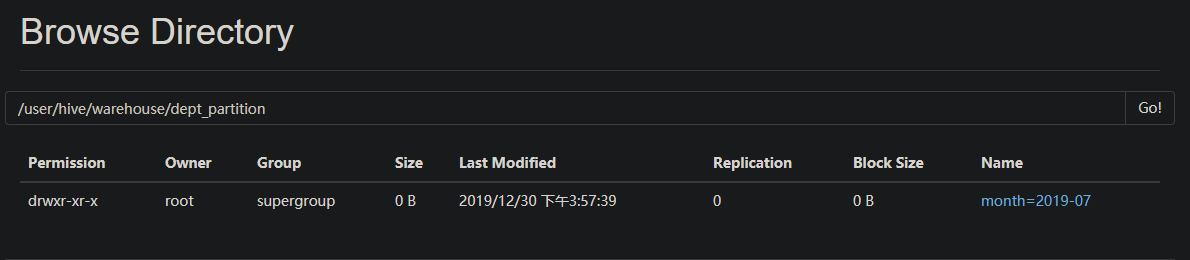
再次加载两个分区
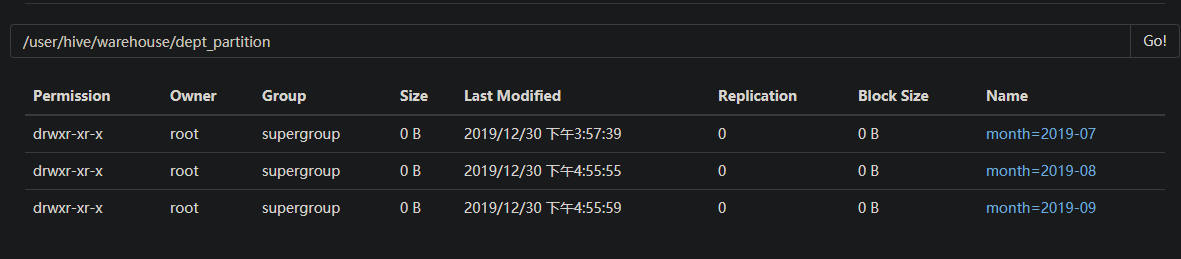
查询数据
1 | hive (default)> select * from dept_partition; |
可以看到,三个分区的数据都能查到,且把分区参数当做了一列 dept_partition.month
利用 where 字句查询某分区的数据
1 | hive (default)> select * from dept_partition where month='2019-08'; |
查看元数据
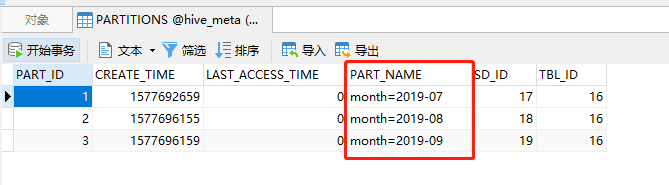
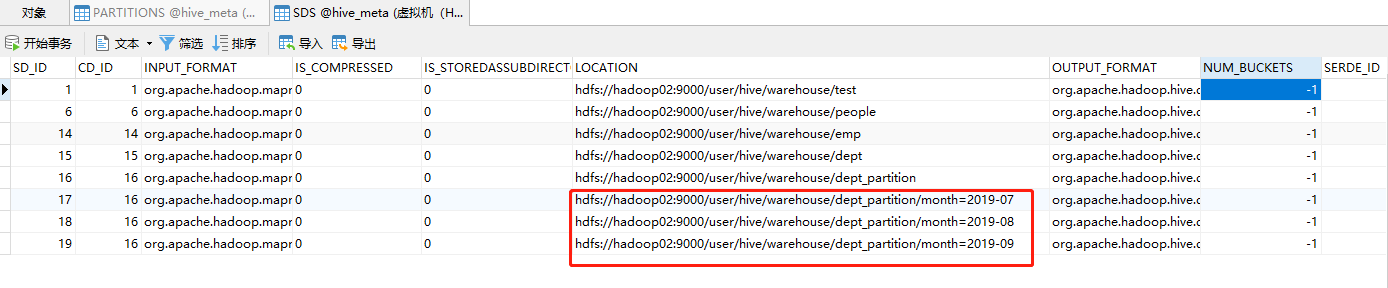
增加分区
1 | hive (default)> alter table dept_partition add partition(month='2019-10'); |
同时添加多个分区
1 | alter table dept_partition add partition(month='2019-11') partition(month='2019-12'); |
删除分区
1 | hive (default)> alter table dept_partition drop partition(month='2019-12'); |
同时删除多个分区
1 | hive (default)> alter table dept_partition drop partition(month='2019-11'), partition(month='2019-10'); |
注意:添加多个分区时,分区与分区之间用 空格 隔开;删除多个分区时,分区与分区之间用 英文逗号 隔开!!
查看分区表有多少分区
1 | hive (default)> show partitions dept_partition; |
查看分区结构
1 | hive (default)> desc formatted dept_partition; |
分区表的注意事项
创建二级分区表
1 | create table dept_partition2( |
与一级分区的区别是 partitioned by 中定义两个字段。
加载数据到二级分区
1 | hive (default)> load data local inpath '/opt/module/hive/tmp_data/dept.txt' into table dept_partition2 partition(month='2019-10', day='30'); |
查看分区数据
1 | hive (default)> select * from dept_partition2 where month='2019-10' and day='30'; |

分区表与数据产生关联的三种方式
上传数据后修复
适用场景:在 HDFS 上存在分区目录,且目录中存在文件,但是元数据中没有对应的分区信息。
以 dept_partition 为例,此时这个分区表只有三个分区

- 创建一个
2019-11文件夹,上传 dept.txt 数据。
1 | [root@hadoop02 tmp_data]# hadoop fs -mkdir -p /user/hive/warehouse/dept_partition/month=2019-10 |
- 查询
month=2019-10分区的数据。
1 | hive (default)> select * from dept_partition where month='2019-10'; |
- 此时,执行分区修复
1 | hive (default)> msck repair table dept_partition; |
- 再次查询分区
1
2
3
4
5
6
7
8hive (default)> select * from dept_partition where month='2019-10';
OK
dept_partition.deptno dept_partition.dname dept_partition.loc dept_partition.month
10 ACCOUNTING 1700 2019-10
20 RESEARCH 1800 2019-10
30 SALES 1900 2019-10
40 OPERATIONS 1700 2019-10
Time taken: 0.088 seconds, Fetched: 4 row(s)
修改表分区
只需要将上述第三步修改为: alter table dept_partition where month='2019-10'
load 数据
将第一种方式的前三步合并为一步: load data local inpath '/file/path' into table table_name partition(partition_name=partition_value)
修改表
表重命名
语法:alter table table_name rename to new_table_name;
此操作会修改元数据和 HDFS 的文件夹名称
1 | hive (default)> alter table test rename to rename_table; |
1 | hive (default)> show tables; |
增加/修改/替换列信息
修改列
语法:alter table table_name CHANGE [column] col_old_name col_new_name column_type [COMMENT col_coment] [FIRST | AFTER column_name]
1 | hive (default)> alter table test CHANGE column name sex int; |
增加、替换列信息
语法:alter table table_name ADD | REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
1 | hive (default)> alter table test add columns (name string); |
注意:ADD 表示增加一个字段,字段位置在所有列的后面(partition列的前面)
REPLACE 是替换表中的 所有字段!不能只替换一个字段
1 | hive (default)> alter table test replace columns (name string); |
删除表
1 | hive (default)> drop table test; |