Hive 是 Facebook 开源的用于解决 海量结构化日志 的数据统计。
Hive 是基于 Hadoop 的数据仓库地址,可以 将结构化的数据文件映射为一张表,并提供 类似 SQL 的查询功能。
Hive 的本质是将 HQL(Hive Query Language) 转化为 MapReduce。
基本概念
- 数据仓库通过 SQL 进行统计分析
- 将 SQL 中常用的操作(select、where、group等)用 MapReduce 写成很多模板
- 将所有的 MapReduce 模板封装到 Hive 中
- 用户根据业务需求,编写响应的 HQL 语句
- HQL 调用 Hive 中的 MapReduce 模板
- 通过模板运行 MapReduce 程序,生成响应的分析结果
- 将运行结果返回给客户端
注意点
Hive 的数据存储在 HDFS 中
Hive 分析数据底层的默认实现是 MapReduce
执行程序运行在 Yarn 上
Hive 的优缺点
优点
操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)
避免了写 MapReduce,减少学习成本、工作量
执行延迟较高,因此常用于数据分析,对实时性要求不高的场合
对于处理大数据有优势,处理小数据没有优势
支持自定义函数,可以根据自己的需求实现自己的函数
缺点
HQL 表达能力有限
迭代式算法无法表达;
数据挖掘方面不擅长;
效率低
Hive 自动生成 MapReduce 作业,通常不够只能
Hive 调优困难,粒度较粗
架构
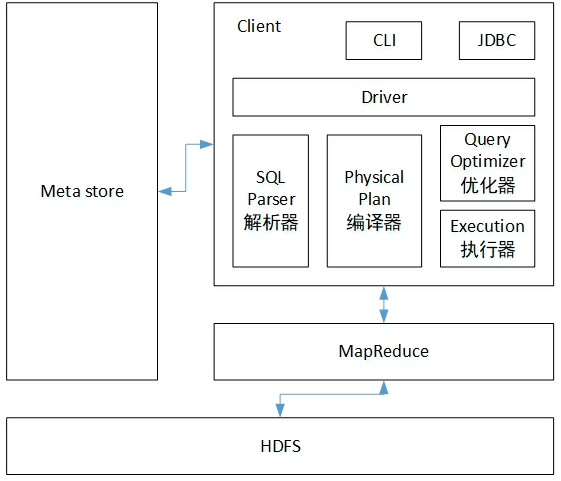
与数据库的比较
Hive 采用了类似于 SQL 的查询语言:HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。
从结构上看,Hive 和数据库除了拥有类似的查询语言外,再无类似之处。
查询语言
由于 SQL 被广泛的应用在数据库中,因此基于 Hive 的特性,设计了类 SQL 的查询语言,熟悉 SQL 的话可以很方便的使用 Hive 做开发
数据存储位置
Hive 是建立在 Hadoop 上的,所有 Hive 的数据都是存储在 HDFS 中,而数据库则可以将数据存储在块设备或本地文件系统中
数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是 读多写少 的,因此,Hive 不建议修改数据,所有的数据都是加载的时候就确定好的。
而数据库中的数据通常是需要进行修改的。
索引
Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 key 建立索引。
Hive 要访问数据中满足条件的特性值,需要 暴力扫描整个数据,因此访问的延迟较高。
由于 MapReduce 的引入,Hive 可以并行访问数据,因此即使没有索引,对于大量数据的访问,Hive 依然有优势。
数据库中,通常会针对一个或几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。
执行
Hive 中大多数查询的执行是通过 Hadoop 的 MapReduce 来实现的,数据库通常有自己的执行引擎
执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。
由于 MapReduce 本身具有较高延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。
数据库的执行延迟较低(在数据规模小的时候)
可扩展性
Hive 是建立在 Hadoop 上的,因此 Hive 的可扩展性和 Hadoop 的可扩展性是高度一致的。
数据库由于 ACID 雨衣的严格限制,扩展非常有限
数据规模
Hive 可以利用 MapReduce 进行并行运算,可以支持很大规模的数据
数据库可支持的数据规模要比 Hive 小很多
安装
示例使用 Hadoop-2.7.2、Hive 1.2.1、MySQL 5.6.24 版本
省略 Hadoop-2.7.2 安装
安装 hive
将 hive-1.2.1 拷贝到 /opt/software 文件夹,并加压到 /opt/module/hive 下
拷贝 conf/hive-env.sh.template 文件为 hive-env.sh
修改 hive-env.sh
1 | HADOOP_HOME=/opt/module/hadoop-2.7.2 |
启动 hive
1 | [root@hadoop02 hive]# bin/hive |
测试 Hive、创建表
查看数据库
1 | hive> show databases; |
进入 default 数据库,创建一张 student 表
1 | hive> use default; |
插入一条数据
1 | hive> insert into student values(1, 'laiyy'); |
插入完成后,查看 HDFS Web UI

再次插入一条数据,查看 WebUI

注意:这个 copy1 并不是真的拷贝的之前 000000_0 的数据!
可以看到,两个文件的大小是不一样的,出现 copy_1 的原因是因为 HDFS 中同一个文件夹下不能出现两个相同名字的文件,所以新插入的数据生成的文件默认拼接了 copy_1,如果再插入数据,则会生成 copy_2、copy_3 以此类推
查看数据
1 | hive> select * from student; |
退出 Hive
1 | hive> quit; |
此例中,insert、select count(*) 时,会运行 MapReduce 程序,其他不会。因为 count(*) 牵扯到计算;insert 牵扯到创建文件(也可以理解为计算)