select deptno, count(*) from emp group by mgr。这条语句如果直接执行是会报错的,此时就可以用窗口函数来解决。
窗口函数
OVER:指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。
OVER 函数可能出现的连接属性:
用在 over 函数内的
CURRENT ROW:当前行
n PRECEDING:往前 n 行数据
n FOLLOWING:往后 n 行数据
UNBOUNDED:起点
UNBOUNDED PRECEDING:从前面的起点
UNBOUNDED FOLLOWING:到后面的起点
用在 over 函数外
LAG(col, n, default_value):往前第 n 行数据
LEAD(col, n, default_value):往后第 n 行数据
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从 1 开始;对于每一行,NTILE 返回慈航所属组的编号;n 必须是 int 类型
根据 测试数据,实现以下需求
需求
需求 1:查询在 2017 年 4 月份购买过的顾客及总人数
需求 2:查询顾客的购买明细及总购买总额
需求 3:基于上述场景,将 cost 按照日期进行累加
需求 4:查询顾客的购买明细及每个顾客的购买总额
需求 5:查询顾客购买明细,并将 cost 按累加金额(与需求 3 不同之处在于需求 3 是累加总额,此需求是累加每个顾客的总额)
需求 6查询顾客上次的购买时间
需求 7查询前 20% 时间的订单信息
创建表
1 | hive (default)> create table business( |
需求 1
1 | select name, count(*) from business where substring(orderdate, 1, 7) = '2017-04' group by name; |
用此语句的查询结果为:
1 | name _c1 |
这个结果是查询出来的是 2017 年 4 月份购买过的顾客,可这个顾客购买的次数,并不是总人数。所以这个方案是不行的。
使用窗口函数进行查询
- 在 count(*) 后加 over()
- count(*) 与 over() 使用空格隔开即可
1 | select name, count(*) over() from business where substring(orderdate, 1, 7) = '2017-04' group by name; |
此时的查询结果是正确的。
1 | name count_window_0 |
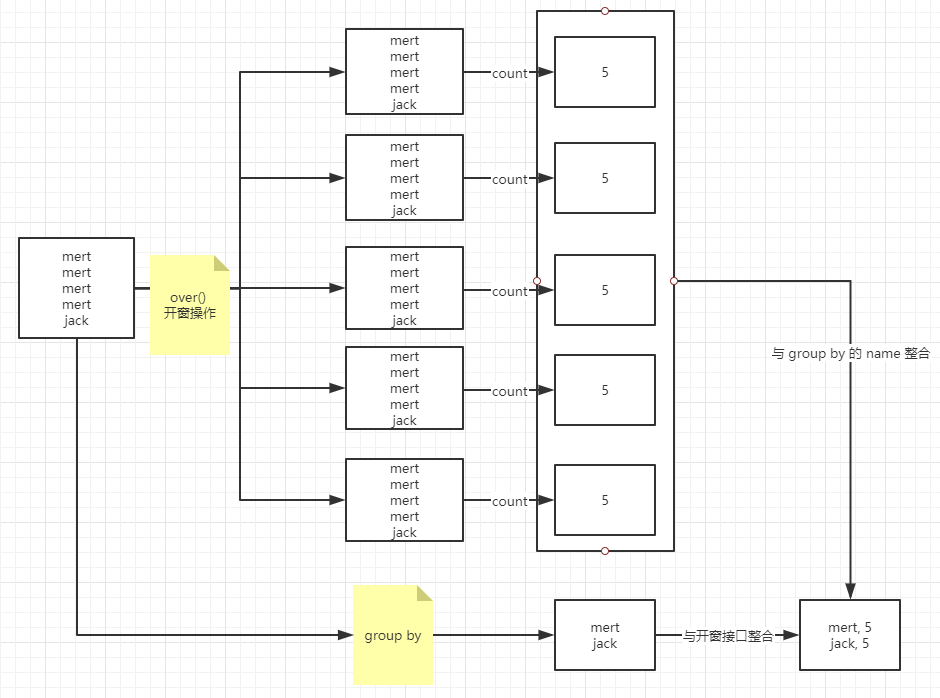
- over() 函数必须跟在
聚合函数的后面 - over() 函数调用时也叫做
开窗,意义在于对整个数据集开了个窗口 - over() 开的窗口仅仅是给 count(*) 这个聚合函数用的
- 对每个数据都开了一个窗口
流程
去掉 count(*) over() 后,运行剩余语句,结果集为
1 | name |
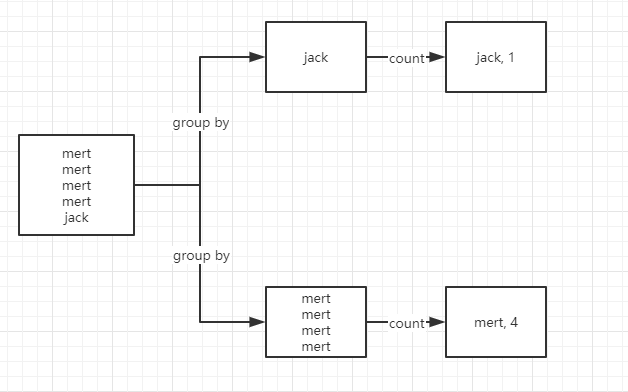
在加上 count(*) over() 后,由于 over() 函数没有传参,代表针对所有结果集生效。此时结果集供有 2 条数据,则会开两个窗口。
即为 mart 开了一个窗,窗口大小是全局的,即为 2,则此时对开窗后的数据进行 count,则 count 为 2;同理 jack 的 count 也为 2。
开窗计算结束后,返回的 count 就是 2,则运行结果就是现在展示出来的样子。
group by 的流程
over 流程
需求 2
1 | hive (default)> select *, sum(cost) over() from business; |
需求 3
可以看到,每个月的总额是当月销售额加上之前月份的销售额的总和。
1 | hive (default)> select orderdate, cost, sum(cost) over(order by orderdate) |
需求 4
思路:按照顾客进行分组。
通常情况下,分组用 group by 即可,但需要注意的是,窗口函数是不能用 group by 的。可以使用类似的 distribute by 来进行操作。
1 | hive (default)> select *, sum(cost) over(distribute by name) from business; |
需求 5
1 | hive (default)> select *, sum(cost) over(distribute by name sort by orderdate) from business; |
需求 6
1 | hive (default)> select *, lag(orderdate, 1, '1970-01-01') over(distribute by name sort by orderdate) from business; |
需求 7
ntile(5) over(order by orderdate):将数组分为 5 个组,按照时间排序
where ntile_5 = 1:查询第一个组,即前 20%
1 | hive (default)> select name, orderdate, cost from ( |
Rank 函数
Rank 排名函数。
RANK():排序相同时会重复,总数不变
DENSE_RANK():排序相同时会重复,总数减少
ROW_NUMER():根据顺序计算
使用 测试数据 测试 Rank 函数
1 | create table score( |
同时测试三种 rank 方式
1 | hive (default)> select *, rank() over(partition by subject order by score desc) rank1, |