在上例中,测试了 HDFS 以及在 HDFS 下执行 MapReduce 示例。本例中,测试启动 YARN,并在 YARN 中执行 MapReduce 程序、并查看历史执行信息和执行日志信息
配置 YARN
配置 yarn-env.sh
修改 yarn-env.sh 中的 JAVA_HOME
1 | vim etc/hadoop/yarn-env.sh |
将第 23 行的注释去掉,修改 JAVA_HOME 为 export JAVA_HOME=/opt/module/jdk1.8.0_144
1 | 22 # some Java parameters |
配置 yarn-site.xml
1 | vim etc/hadoop/yarn-site.xml |
配置 mapred-env.sh
修改 mapred-env.sh 的 JAVA_HOME:第 16 行去掉注释,修改 JAVA_HOME 为 export JAVA_HOME=/opt/module/jdk1.8.0_144
创建并修改 mapred-site.xml 文件
拷贝 etc/hadoop/mapred-site.xml.template 文件为 mapred-site.xml 文件,指定 MR 运行在 YARN 上
1 | cp mapred-site.xml.template mapred-site.xml |
启动 YARN
在保证 NameNode 和 DataNode 启动的情况下,启动 ResourceManager 和 NodeManager。
进入 /opt/module/hadoop-2.7.2,利用 yarn-daemon.sh 启动。 注意启动顺序:ResourceManager 先启动
1 | sbin/yarn-daemon.sh start resourcemanager |
查看是否启动成功
1 | [root@hadoop01 hadoop-2.7.2]# jps |
查看 Web UI
访问 hadoop01:50070,hdfs 正常使用,继续访问 hadoop01:8088,查看 MapReduce 程序运行进程
50070:HDFS
8088:MapReduce
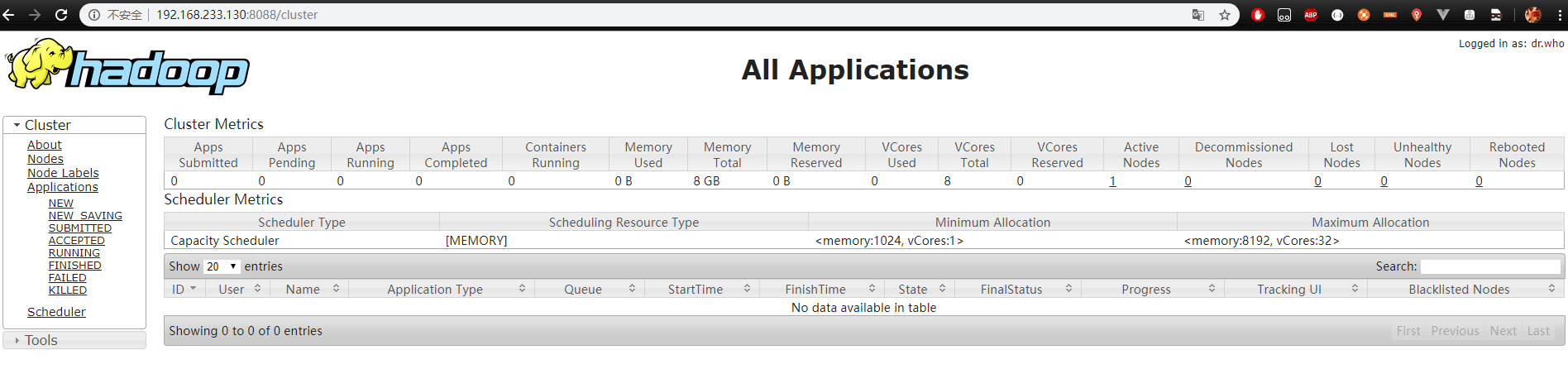
测试 8088 的 MapReduce
删除 hdfs 中的 /user/laiyy/output: bin/hdfs dfs -rm -r /user/laiyy/output
执行 MapReduce word count
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/laiyy/input /user/laiyy/output |
控制台打印日志如下:
1 |
|
在什么地方执行的任务:The url to track the job: http://hadoop01:8088/proxy/application_1568971486858_0001/
map、reduce 执行流程:map x% reduce x%
执行结果:Job job_1568971486858_0001 completed successfully
在 8088 上查看执行信息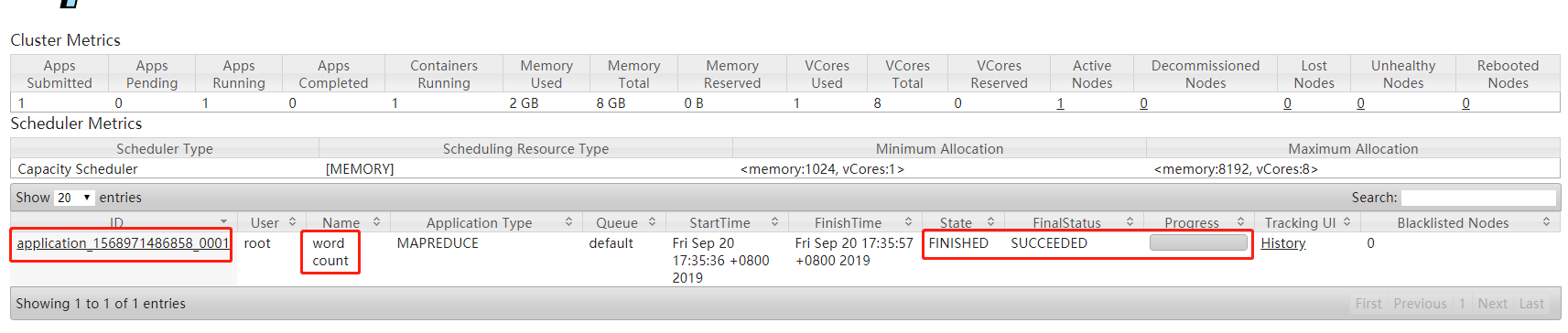
配置 Yarn 历史运行服务器
在 8088 上,某任务执行结束后,可以在进度条后看到有一个 history 选项卡,此选项卡可以查看历史运行记录。但是在没有配置历史运行服务器的时候,此选项卡打开后是 404,要想看到历史执行记录,需要配置 历史运行服务器
配置方式:
- 修改 mapred-site.xml 文件
- 启动历史服务器
- 查看 JobHistory
- 修改 mapred-site.xml 文件
打开 mapred-site.xml 文件,增加如下配置
1 | <configuration> |
- 启动历史服务器
执行命令 sbin/mr-jobhistory-daemon.sh start historyserver
查看启动是否成功
1 | [root@hadoop01 hadoop-2.7.2]# jps |
访问 8088 中的 history 选项卡,查看历史执行记录
如果出现下面的情况,是因为在本机没有在 hosts 配置 hadoop01 的地址,修改本机 hosts 文件,增加上 hadoop01 的映射即可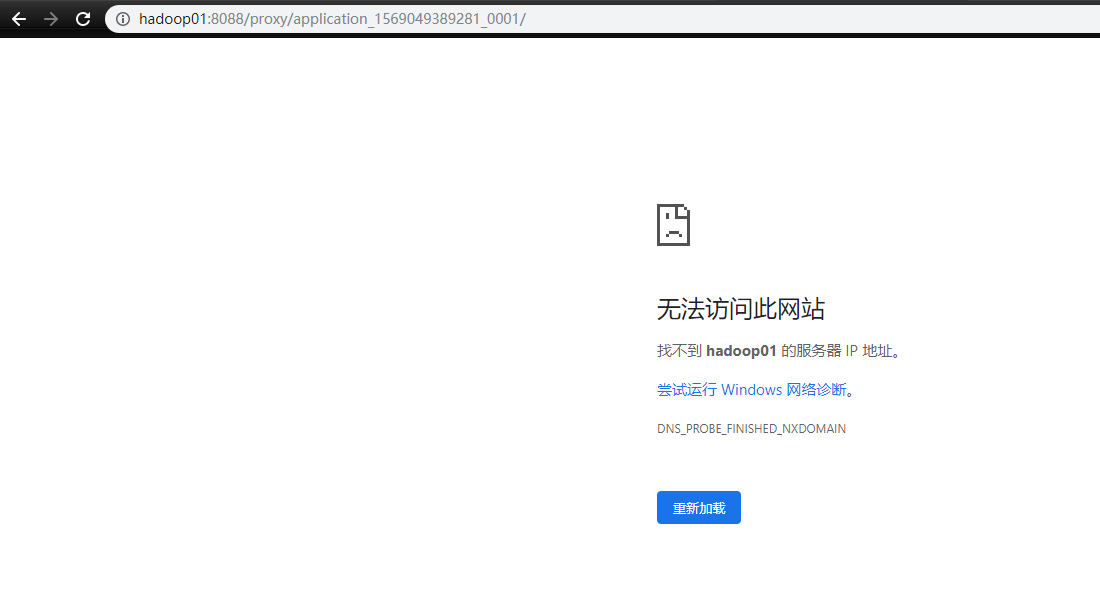
配置好 hosts 后,刷新页面,即可看到该任务的执行流程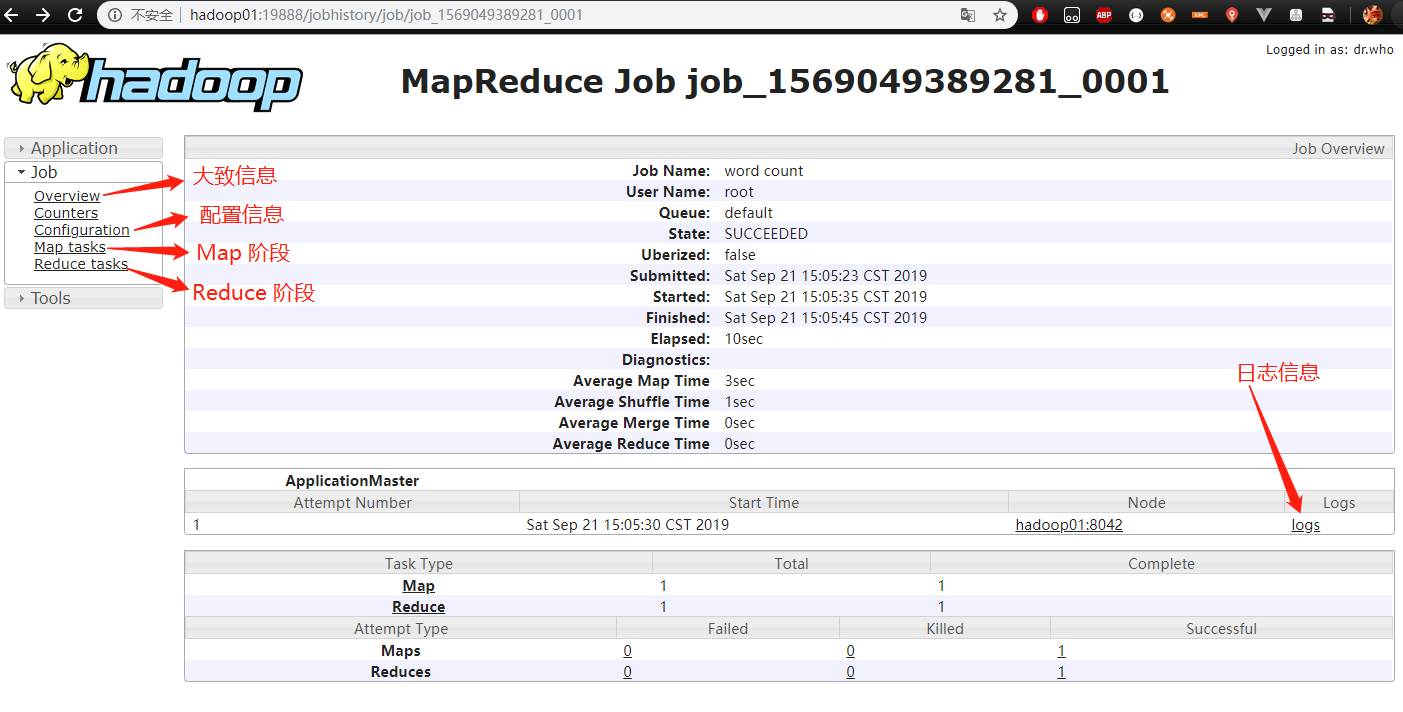
日志服务器
Logs 选项卡可以查看整个执行过程的相关日志,此时点击 Logs 选项卡,会提示如下信息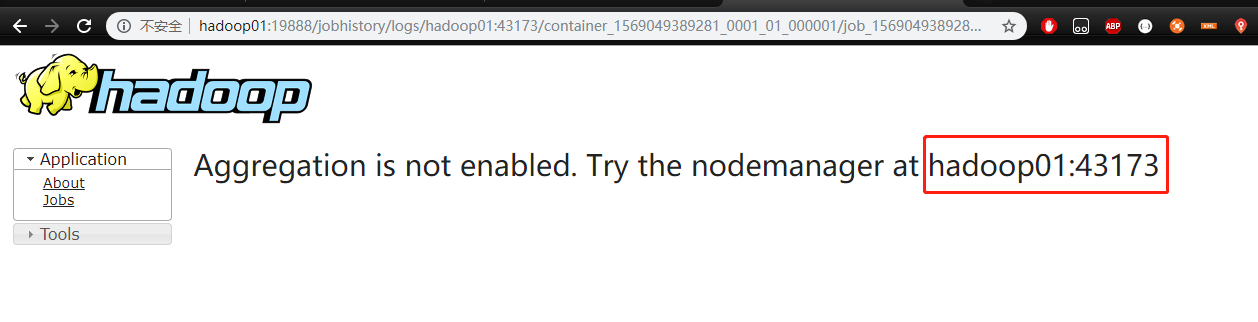
按照提示信息,我们需要配置 日志服务器
日志聚集的概念:应用运行完成后,将程序运行日志的信息上传到 HDFS 系统上
日志聚集的好处:可以方便的查看到程序运行详情,方便开发调试
注意:
开启日志聚集功能,需要重启 NodeManager、ResourceManager、HistoryManager
开启日志聚集的步骤:
- 停止服务
- 修改配置
yarn-site.xml- 重新启动
- 执行测试
- 停止服务
1 | [root@hadoop01 hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh stop historyserver |
- 配置 yarn-site.xml
1 | <configuration> |
- 重新启动
1 | [root@hadoop01 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager |
- 执行测试
删除 hdfs 上的 output 文件夹,重新执行 word count 示例
1 | bin/hdfs dfs -rm -r /user/laiyy/output |
在 8088 上选择最后一个执行的任务,进入 history 选项卡,再进入 Logs 选项卡查看结果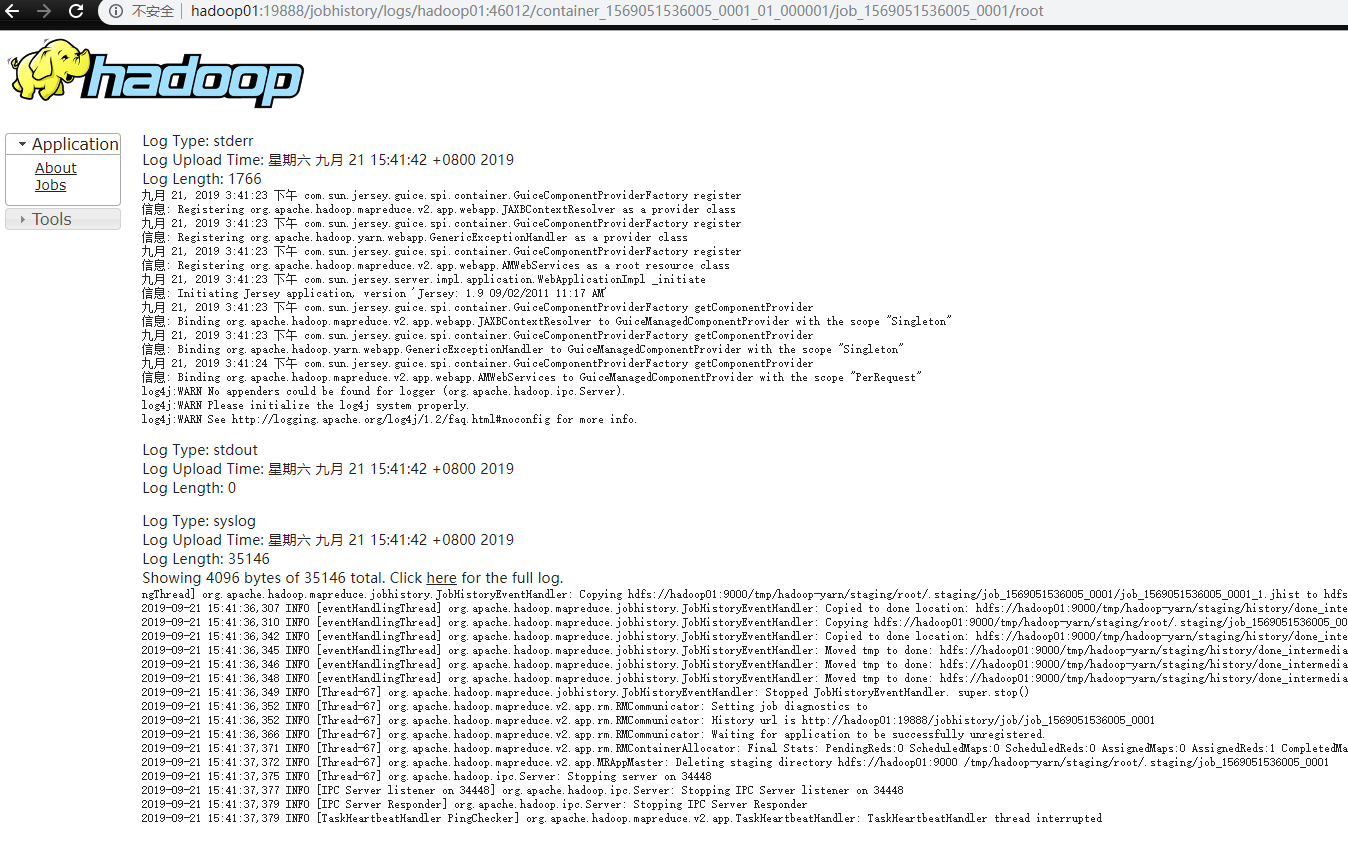
配置文件的说明
Hadoop 配置文件分为量类:默认配置文件、自定义配置文件。自定义配置文件的优先级更高
默认配置文件
| 默认配置文件 | 存放位置 |
|---|---|
| core-default.xml | hadoop-common-xxx.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-xxx.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-xxx.jar/yarn-default.xml |
| mapred-defaultt.xml | hadoop-mapreduce-client-core-xxx.jar/mapred-default.xml |
自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 存放在 $HADOOP_HOME/etc/hadoop 文件夹下,可根据需求修改配置