在此前,已经成功启动、测试了 hadoop 集群的功能,了解了部分 hadoop 知识,下面就需要开始针对 hadoop 进行继续深入学习 HDFS、MapReduce 的知识。
HDFS 概述
HDFS 是一种分布式文件管理系统,用于文件存储,通过目录树来定位文件;其次,由于是分布式的,由多台服务器联合起来实现功能。
HDFS 使用场景:适合一次写入、多次独处的场景,且不支持文件的修改,适合用于做数据分析,不适合做网盘应用。
HDFS 的优缺点
优点
高容错性
数据自动保存多个副本。通过增加副本的形式,提供了容错性。默认 3 个副本,当有其中一个副本挂掉了,会在其他服务器上再增加一个副本,保证最多有三个副本存在。且三个副本不能在同一个机器上
适合处理大数据
数据规模:能够处理 GB、TB、PB 级别数据
文件规模:能够处理百万以上的文件数量
可以构建在廉价机器上,通过多副本机制,提高可靠性
缺点
不适合低延迟数据访问:如毫秒级数据存储
无法高效的对大量小文件进行存储
存储大量小文件的话,会占用 NameNode 大量内存来存储文件目录和块信息,这样是不可取的。NameNode 的内存总是有限的
小文件存储的寻址时间会超过读取时间,违反了 HDFS 的设计目标
不支持并发写入、文件随机修改
一个文件只能有一个写,不允许多个线程同时写
仅支持数据的追加(append),不支持文件随机修改
HDFS 组成架构
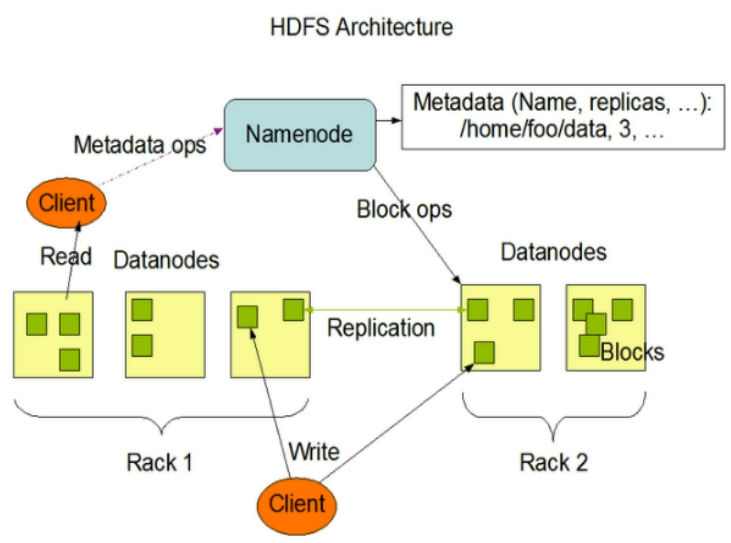
NameNode(nn):就是 Master,是一个管理者
管理HDFS 的命名空间;配置副本策略;管理数据块映射信息;处理客户端读写请求
DataNode:就是 Slave。NameNode 下达命令,DataNode 执行实际操作。
存储实际的数据块;执行数据块的读/写操作
Client:客户端
- 文件切分。文件上传到 HDFS 的时候,Client 将文件切分成一个一个的 Block(默认 128M)然后进行上传
- 与 NameNode 交互,获取文件位置信息
- 与 DataNode 交互,读取、写入数据
- 提供一些命令管理 HDFS,如 NameNode 格式化
- 通过一些命令访问 HDFS,如对 HDFS 的增删改查
Secondary NameNode:非 NameNode 热备,当 NameNode 挂掉后,并不会马上替换 NameNode 提供服务
- 辅助 NameNode,分担其工作,如:定期合并 Fsimage(镜像文件)、Edits(编辑日志),并推送到 NameNode
- 紧急情况下辅助恢复 NameNode,但是可能会丢失数据
HDFS 文件块大小
HDFS 中的文件上是分块存储(Block),大小可通过参数配置 (dfs.blocksize),默认在 2.X 中为 128M,1.X 为 64M
HDFS 块大小设置主要取决于磁盘传输速度。
自带 Shell 操作
基本语法
bin/hadoop fs 具体命令
bin/hdfs dfs 具体命令
常用命令
启动集群
1
2sbin/start-dfs.sh
sbin/start-yarn.sh获取帮助文档
1
hadoop fs -help [command]
查看 HDFS 目录信息
1
2hadoop fs -ls
hadoop fs -l -R [dir path] # 递归查询在 HDFS 上创建目录
1
hadoop fs -mkdir -p [your dir path]# 创建多级目录
将本地文件剪切到 HDFS
1
hadoop fs -moveFromLocal [local file] [hdfs]
追加一个文件到已经存在的文件末尾
1
hadoop fs -appendToFile [local file] [hdfs]
可能的报错信息 1:
1 | appendToFile: Failed to APPEND_FILE /user/laiyy/haha.txt for DFSClient_NONMAPREDUCE_-1628325628_1 on 192.168.233.131 because lease recovery is in progress. Try again later. |
可能的报错信息 2:
1 | ava.io.IOException: Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try. (Nodes: current=[DatanodeInfoWithStorage[192.168.233.131:50010,DS-f6860e33-55fb-44b1-9b95-4a61b0264267,DISK], DatanodeInfoWithStorage[192.168.233.133:50010,DS-8191d13c-f9c0-4d3c-8e3d-fa29d8a76ee5,DISK]], original=[DatanodeInfoWithStorage[192.168.233.131:50010,DS-f6860e33-55fb-44b1-9b95-4a61b0264267,DISK], DatanodeInfoWithStorage[192.168.233.133:50010,DS-8191d13c-f9c0-4d3c-8e3d-fa29d8a76ee5,DISK]]). The current failed datanode replacement policy is DEFAULT, and a client may configure this via 'dfs.client.block.write.replace-datanode-on-failure.policy' in its configuration. |
错误原因:
1、使用 jps 查看三台机器上的 DataNode 是否都存在,如果缺少了某个 DataNode,则会出现这种错误。
2、如果三台 DataNode 都存在,则查看三台机器上的 %HADOOP_HOME%/data/dfs/data/current/VERSION 和 %HADOOP_HOME%/data/dfs/name/current/VERSION 文件,对比三台机器上的文件,查看 namenode 的 namespaceID、clusterID 是否一致,查看 datanode 的 storageID、clusterID 是否一致。如果不一致,则会出现这种错误。
解决办法:
第一步:停止集群
sbin/stop-dfs.sh、sbin/stop-yarn.sh
第二步:删除%HADOOP_HOME%/data下的数据
第三步:格式化 NameNodebin/hdfs namenode -format
第四步:重启集群sbin/start-dfs.sh、sbin/start-yarn.sh
- 将本地文件复制到 HDFS
1 | hadoop fs -copyFromLocal [local file] [hdfs] |
- 从 HDFS 拷贝到本地
1 | hadoop fs -copyToLocal [hdfs] [local path] |
- 从 HDFS 的一个路径,拷贝到另外一个路径
1 | hadoop fs -cp [hdfs] [hdfs] |
- 从 HDFS 的一个路径,剪切到另外一个路径
1 | hadoop fs -mv [hdfs] [hdfs] |
- 合并下载多个文件
1 | hadoop fs -getmerge [hadfs] [local path] |
- 查看文件
1 | hadoop fs -tail [hdfs txt file] |
- 删除文件
1 | hadoop fs -rm [hdfs] |
- 删除空目录
1 | hadoop fs -rmdir [hdfs empty dir] |
- 统计文件夹大小信息
1 | hadoop fs -du -s -h [hdfs] |
- 设置 HDFS 文件副本数量
1 | hadoop fs -setrep [num] [hdfs] |
HDFS 客户端环境测试
pom
1 | <dependencies> |
测试使用客户端创建目录
1 | Configuration configuration = new Configuration(); |
运行结果:
1 | org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="/laiyy":root:supergroup:drwxr-xr-x |
错误原因: 使用 win10 调用 hadoop,用户为 Administrator,而 HDFS 的用户为 root,用户权限不足
解决方法: 在运行 main 方法时,动态的给定一hadoop用户值。
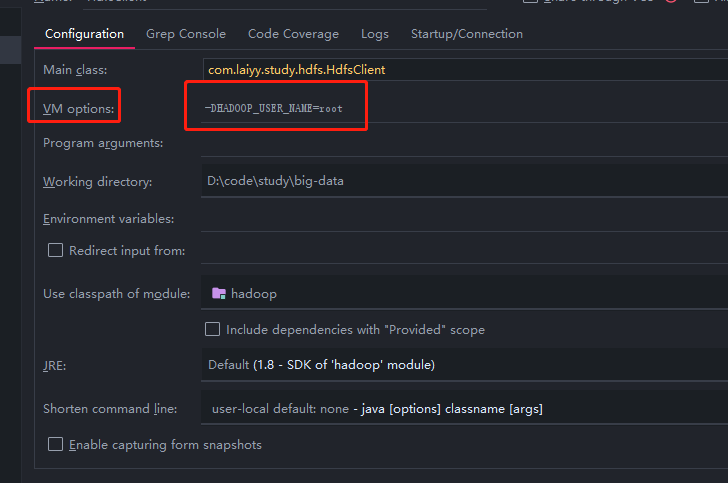
再次运行:
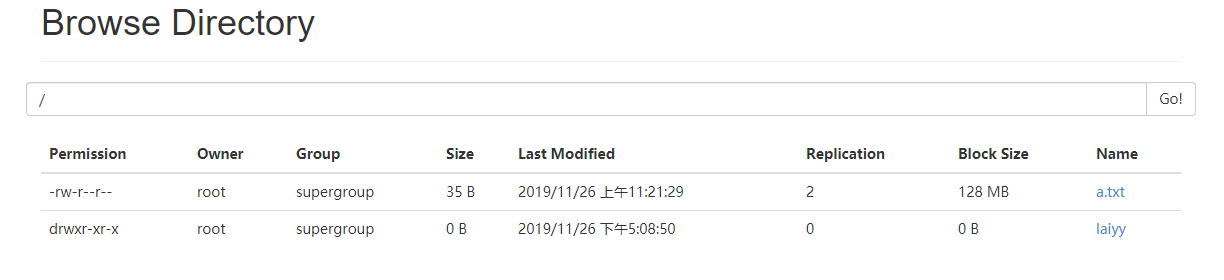
另一种方式
1 | Configuration configuration = new Configuration(); |